








____ _ ____
/ __ \ (_)____ / __ \ __ __ ____
/ / / // // __ \ / / / // / / // __ \
/ /_/ // // /_/ // /_/ // /_/ // /_/ /
/_____//_// .___//_____/ \__,_// .___/
/_/ /_/
DipDup is a Python framework for building smart contract indexers. It helps developers focus on business logic instead of writing a boilerplate to store and serve data. DipDup-based indexers are selective, which means only required data is requested. This approach allows to achieve faster indexing times and decreased load on underlying APIs.
-
Ready to build your first indexer? Head to Quickstart.
-
Looking for examples? Check out Demo Projects and Built with DipDup pages.
-
Want to participate? Vote for open issues, join discussions or become a sponsor.
-
Have a question? Join our Discord or tag @dipdup_io on Twitter.
This project is maintained by the Baking Bad team.
Development is supported by Tezos Foundation.
Thanks
Sponsors
Decentralized web requires decentralized funding. The following people and organizations help the project to be sustainable.
Want your project to be listed here? We have nice perks for sponsors! Visit our GitHub Sponsors page.
Contributors
We are grateful to all the people who help us with the project.
- @852Kerfunkle
- @Anshit01
- @arrijabba
- @Fitblip
- @gdsoumya
- @herohthd
- @Karantezsure
- @mystdeim
- @nikos-kalomoiris
- @pravind
- @sbihel
- @tezosmiami
- @tomsib2001
- @TristanAllaire
- @veqtor
- @xflpt
If we forgot to mention you, or you want to update your record, please, open an issue or pull request.
Quickstart
This page will guide you through the steps to get your first selective indexer up and running in a few minutes without getting too deep into the details.
Let's create an indexer for the tzBTC FA1.2 token contract. Our goal is to save all token transfers to the database and then calculate some statistics of its holders' activity.
A modern Linux/macOS distribution with Python 3.10 installed is required to run DipDup.
Create a new project
Interactively (recommended)
You can initialize a hello-world project interactively by choosing configuration options in the terminal. The following command will install DipDup for the current user:
curl -Lsf https://dipdup.io/install.py | python
Now, let's create a new project:
dipdup new
Follow the instructions; the project will be created in the current directory. You can skip reading the rest of this page and slap dipdup run instead.
From scratch
Currently, we mainly use Poetry for dependency management in DipDup. If you prefer hatch, pdb, piptools or others — use them instead. Below are some snippets to get you started.
# Create a new project directory
mkdir dipdup-indexer; cd dipdup-indexer
# Plain pip
python -m venv .venv
. .venv/bin/activate
pip install dipdup
# or Poetry
poetry init --python ">=3.10,<3.11"
poetry add dipdup
poetry shell
Write a configuration file
DipDup configuration is stored in YAML files of a specific format. Create a new file named dipdup.yml in your current working directory with the following content:
spec_version: 1.2
package: demo_token
database:
kind: sqlite
path: demo-token.sqlite3
contracts:
tzbtc_mainnet:
address: KT1PWx2mnDueood7fEmfbBDKx1D9BAnnXitn
typename: tzbtc
datasources:
tzkt_mainnet:
kind: tzkt
url: https://api.tzkt.io
indexes:
tzbtc_holders_mainnet:
template: tzbtc_holders
values:
contract: tzbtc_mainnet
datasource: tzkt_mainnet
templates:
tzbtc_holders:
kind: operation
datasource: <datasource>
contracts:
- <contract>
handlers:
- callback: on_transfer
pattern:
- destination: <contract>
entrypoint: transfer
- callback: on_mint
pattern:
- destination: <contract>
entrypoint: mint
Initialize project tree
Now it's time to generate typeclasses and callback stubs. Run the following command:
dipdup init
DipDup will create a Python package demo_token having the following structure:
demo_token
├── graphql
├── handlers
│ ├── __init__.py
│ ├── on_mint.py
│ └── on_transfer.py
├── hooks
│ ├── __init__.py
│ ├── on_reindex.py
│ ├── on_restart.py
│ ├── on_index_rollback.py
│ └── on_synchronized.py
├── __init__.py
├── models.py
├── sql
│ ├── on_reindex
│ ├── on_restart
│ ├── on_index_rollback
│ └── on_synchronized
└── types
├── __init__.py
└── tzbtc
├── __init__.py
├── parameter
│ ├── __init__.py
│ ├── mint.py
│ └── transfer.py
└── storage.py
That's a lot of files and directories! But don't worry, we will need only models.py and handlers modules in this guide.
Define data models
Our schema will consist of a single model Holder having several fields:
address— account addressbalance— in tzBTCvolume— total transfer/mint amount bypassedtx_count— number of transfers/mintslast_seen— time of the last transfer/mint
Put the following content in the models.py file:
from tortoise import fields
from dipdup.models import Model
class Holder(Model):
address = fields.CharField(max_length=36, pk=True)
balance = fields.DecimalField(decimal_places=8, max_digits=20, default=0)
turnover = fields.DecimalField(decimal_places=8, max_digits=20, default=0)
tx_count = fields.BigIntField(default=0)
last_seen = fields.DatetimeField(null=True)
Implement handlers
Everything's ready to implement an actual indexer logic.
Our task is to index all the balance updates, so we'll start with a helper method to handle them. Create a file named on_balance_update.py in the handlers package with the following content:
from datetime import datetime
from decimal import Decimal
import demo_token.models as models
async def on_balance_update(
address: str,
balance_update: Decimal,
timestamp: datetime,
) -> None:
holder, _ = await models.Holder.get_or_create(address=address)
holder.balance += balance_update
holder.turnover += abs(balance_update)
holder.tx_count += 1
holder.last_seen = timestamp
await holder.save()
Three methods of tzBTC contract can alter token balances — transfer, mint, and burn. The last one is omitted in this tutorial for simplicity. Edit corresponding handlers to call the on_balance_update method with data from matched operations:
on_transfer.py
from decimal import Decimal
from demo_token.handlers.on_balance_update import on_balance_update
from demo_token.types.tzbtc.parameter.transfer import TransferParameter
from demo_token.types.tzbtc.storage import TzbtcStorage
from dipdup.context import HandlerContext
from dipdup.models import Transaction
async def on_transfer(
ctx: HandlerContext,
transfer: Transaction[TransferParameter, TzbtcStorage],
) -> None:
if transfer.parameter.from_ == transfer.parameter.to:
# NOTE: Internal tzBTC transfer
return
amount = Decimal(transfer.parameter.value) / (10**8)
await on_balance_update(
address=transfer.parameter.from_,
balance_update=-amount,
timestamp=transfer.data.timestamp,
)
await on_balance_update(
address=transfer.parameter.to,
balance_update=amount,
timestamp=transfer.data.timestamp,
)
on_mint.py
from decimal import Decimal
from demo_token.handlers.on_balance_update import on_balance_update
from demo_token.types.tzbtc.parameter.mint import MintParameter
from demo_token.types.tzbtc.storage import TzbtcStorage
from dipdup.context import HandlerContext
from dipdup.models import Transaction
async def on_mint(
ctx: HandlerContext,
mint: Transaction[MintParameter, TzbtcStorage],
) -> None:
amount = Decimal(mint.parameter.value) / (10**8)
await on_balance_update(
address=mint.parameter.to,
balance_update=amount,
timestamp=mint.data.timestamp,
)
And that's all! We can run the indexer now.
Run your indexer
dipdup run
DipDup will fetch all the historical data and then switch to realtime updates. Your application data has been successfully indexed!
Getting started
This part of the docs covers the same features the Quickstart article does but is more focused on details.
Installation
This page covers the installation of DipDup in different environments.
Host requirements
A Linux/MacOS environment with Python 3.10 installed is required to use DipDup. Other UNIX-like systems should work but are not supported officially.
Minimum hardware requirements are 256 MB RAM, 1 CPU core, and some disk space for the database. RAM requirements increase with the number of indexes.
Non-UNIX environments
Windows is not officially supported, but there's a possibility everything will work fine. In case of issues throw us a message and use WSL or Docker.
We aim to improve cross-platform compatibility in future releases (issue).
Local installation
Interactively (recommended)
The following command will install DipDup for the current user:
curl -Lsf https://dipdup.io/install.py | python
This script uses pipx under the hood to install dipdup and datamodel-codegen as CLI tools. Then you can use any package manager of your choice to manage versions of DipDup and other project dependencies.
Manually
Currently, we mainly use Poetry for dependency management in DipDup. If you prefer hatch, pdb, piptools or others — use them instead. Below are some snippets to get you started.
# Create a new project directory
mkdir dipdup-indexer; cd dipdup-indexer
# Plain pip
python -m venv .venv
. .venv/bin/activate
pip install dipdup
# or Poetry
poetry init --python ">=3.10,<3.11"
poetry add dipdup
poetry shell
Docker
See 6.2. Running in Docker page.
Core concepts
Big picture
Initially, DipDup was heavily inspired by The Graph Protocol, but there are several differences. The most important one is that DipDup indexers are completely off-chain.
DipDup utilizes a microservice approach and relies heavily on existing solutions, making the SDK very lightweight and allowing developers to switch API engines on demand.
DipDup works with operation groups (explicit operation and all internal ones, a single contract call) and Big_map updates (lazy hash map structures, read more) — until fully-fledged protocol-level events are not implemented in Tezos.
Consider DipDup a set of best practices for building custom backends for decentralized applications, plus a toolkit that spares you from writing boilerplate code.
DipDup is tightly coupled with TzKT API but can generally use any data provider which implements a particular feature set. TzKT provides REST endpoints and Websocket subscriptions with flexible filters enabling selective indexing and returns "humanified" contract data, which means you don't have to handle raw Michelson expressions.
DipDup offers PostgreSQL + Hasura GraphQL Engine combo out-of-the-box to expose indexed data via REST and GraphQL with minimal configuration. However, you can use any database and API engine (e.g., write API backend in-house).

How it works
From the developer's perspective, there are three main steps for creating an indexer using the DipDup framework:
- Write a declarative configuration file containing all the inventory and indexing rules.
- Describe your domain-specific data models.
- Implement the business logic, which is how to convert blockchain data to your models.
As a result, you get a service responsible for filling the database with the indexed data.
Within this service, there can be multiple indexers running independently.
Atomicity and persistency
DipDup applies all updates atomically block by block. In case of an emergency shutdown, it can safely recover later and continue from the level it ended. DipDup state is stored in the database per index and can be used by API consumers to determine the current indexer head.
Here are a few essential things to know before running your indexer:
- Ensure that the database (or schema in the case of PostgreSQL) you're connecting to is used by DipDup exclusively. Changes in index configuration or models require DipDup to drop the whole database (schema) and start indexing from scratch. You can, however, mark specific tables as immune to preserve them from being dropped.
- Changing index config triggers reindexing. Also, do not change aliases of existing indexes in the config file without cleaning up the database first. DipDup won't handle that automatically and will treat the renamed index as new.
- Multiple indexes pointing to different contracts should not reuse the same models (unless you know what you are doing) because synchronization is done sequentially by index.
Schema migration
DipDup does not support database schema migration: if there's any model change, it will trigger reindexing. The rationale is that it's easier and faster to start over than handle migrations that can be of arbitrary complexity and do not guarantee data consistency.
DipDup stores a hash of the SQL version of the DB schema and checks for changes each time you run indexing.
Handling chain reorgs
Reorg messages signaling chain reorganizations. That means some blocks, including all operations, are rolled back in favor of another with higher fitness. Chain reorgs happen regularly (especially in testnets), so it's not something you can ignore. These messages must be handled correctly -- otherwise, you will likely accumulate duplicate or invalid data.
Singe version 6.0 DipDup processes chain reorgs seamlessly restoring a previous database state. You can implement your rollback logic by editing the on_index_rollback event hook.
Creating config
Developing a DipDup indexer begins with creating a YAML config file. You can find a minimal example to start indexing on the Quickstart page.
General structure
DipDup configuration is stored in YAML files of a specific format. By default, DipDup searches for dipdup.yml file in the current working directory, but you can provide any path with a -c CLI option.
DipDup config file consists of several logical blocks:
| Header | spec_version* | 14.15. spec_version |
package* | 14.12. package | |
| Inventory | database | 14.5. database |
contracts | 14.3. contracts | |
datasources | 14.6. datasources | |
custom | 14.4. custom | |
| Index definitions | indexes | 14.9. indexes |
templates | 14.16. templates | |
| Hook definitions | hooks | 14.8. hooks |
jobs | 14.10. jobs | |
| Integrations | hasura | 14.7. hasura |
sentry | 14.14. sentry | |
prometheus | 14.13. prometheus | |
| Tunables | advanced | 14.2. advanced |
logging | 14.11. logging |
Header contains two required fields, package and spec_version. They are used to identify the project and the version of the DipDup specification. All other fields in the config are optional.
Inventory specifies contracts that need to be indexed, datasources to fetch data from, and the database to store data in.
Index definitions define the index templates that will be used to index the contract data.
Hook definitions define callback functions that will be called manually or on schedule.
Integrations are used to integrate with third-party services.
Tunables affect the behavior of the whole framework.
Merging config files
DipDup allows you to customize the configuration for a specific environment or workflow. It works similarly to docker-compose anchors but only for top-level sections. If you want to override a nested property, you need to recreate a whole top-level section. To merge several DipDup config files, provide the -c command-line option multiple times:
dipdup -c dipdup.yml -c dipdup.prod.yml run
Run config export command if unsure about the final config used by DipDup.
Full example
This page or paragraph is yet to be written. Come back later.
Let's put it all together. The config below is an artificial example but contains almost all available options.
spec_version: 1.2
package: my_indexer
database:
kind: postgres
host: db
port: 5432
user: dipdup
password: changeme
database: dipdup
schema_name: public
immune_tables:
- token_metadata
- contract_metadata
contracts:
some_dex:
address: KT1K4EwTpbvYN9agJdjpyJm4ZZdhpUNKB3F6
typename: quipu_fa12
datasources:
tzkt_mainnet:
kind: tzkt
url: https://api.tzkt.io
my_api:
kind: http
url: https://my_api.local/v1
ipfs:
kind: ipfs
url: https://ipfs.io/ipfs
coinbase:
kind: coinbase
metadata:
kind: metadata
url: https://metadata.dipdup.net
network: mainnet
indexes:
operation_index_from_template:
template: operation_template
values:
datasource: tzkt
contract: some_dex
big_map_index_from_template:
template: big_map_template
values:
datasource: tzkt
contract: some_dex
first_level: 1
last_level: 46963
skip_history: never
factory:
kind: operation
datasource: tzkt
types:
- origination
contracts:
- some_dex
handlers:
- callback: on_factory_origination
pattern:
- type: origination
similar_to: some_dex
templates:
operation_template:
kind: operation
datasource: <datasource>
types:
- origination
- transaction
contracts:
- <contract>
handlers:
- callback: on_origination
pattern:
- type: origination
originated_contract: <contract>
- callback: on_some_call
pattern:
- type: transaction
destination: <contract>
entrypoint: some_call
big_map_template:
kind: big_map
datasource: <datasource>
handlers:
- callback: on_update_records
contract: <name_registry>
path: store.records
- callback: on_update_expiry_map
contract: <name_registry>
path: store.expiry_map
hooks:
calculate_stats:
callback: calculate_stats
atomic: False
args:
major: bool
jobs:
midnight_stats:
hook: calculate_stats
crontab: "0 0 * * *"
args:
major: True
sentry:
dsn: https://localhost
environment: dev
debug: False
prometheus:
host: 0.0.0.0
hasura:
url: http://hasura:8080
admin_secret: changeme
allow_aggregations: False
camel_case: true
select_limit: 100
advanced:
early_realtime: True
merge_subscriptions: False
postpone_jobs: False
metadata_interface: False
skip_version_check: False
scheduler:
apscheduler.job_defaults.coalesce: True
apscheduler.job_defaults.max_instances: 3
reindex:
manual: wipe
migration: exception
rollback: ignore
config_modified: exception
schema_modified: exception
rollback_depth: 2
crash_reporting: False
logging: verbose
Project structure
The structure of the DipDup project package is the following:
demo_token
├── graphql
├── handlers
│ ├── __init__.py
│ ├── on_mint.py
│ └── on_transfer.py
├── hasura
├── hooks
│ ├── __init__.py
│ ├── on_reindex.py
│ ├── on_restart.py
│ ├── on_index_rollback.py
│ └── on_synchronized.py
├── __init__.py
├── models.py
├── sql
│ ├── on_reindex
│ ├── on_restart
│ ├── on_index_rollback
│ └── on_synchronized
└── types
├── __init__.py
└── tzbtc
├── __init__.py
├── parameter
│ ├── __init__.py
│ ├── mint.py
│ └── transfer.py
└── storage.py
| path | description |
|---|---|
graphql | GraphQL queries for Hasura (*.graphql) |
handlers | User-defined callbacks to process matched operations and big map diffs |
hasura | Arbitrary Hasura metadata (*.json) |
hooks | User-defined callbacks to run manually or by schedule |
models.py | Tortoise ORM models |
sql | SQL scripts to run from callbacks (*.sql) |
types | Codegened Pydantic typeclasses for contract storage/parameter |
DipDup will generate all the necessary directories and files inside the project's root on init command. These include contract type definitions and callback stubs to be implemented by the developer.
Type classes
DipDup receives all smart contract data (transaction parameters, resulting storage, big_map updates) in normalized form (read more about how TzKT handles Michelson expressions) but still as raw JSON. DipDup uses contract type information to generate data classes, which allow developers to work with strictly typed data.
DipDup generates Pydantic models out of JSONSchema. You might want to install additional plugins (PyCharm, mypy) for convenient work with this library.
The following models are created at init for different indexes:
operation: storage type for all contracts in handler patterns plus parameter type for all destination+entrypoint pairs.big_map: key and storage types for all used contracts and big map paths.event: payload types for all used contracts and tags.
Other index kinds do not use code generated types.
Nested packages
Callback modules don't have to be in top-level hooks/handlers directories. Add one or multiple dots to the callback name to define nested packages:
package: indexer
hooks:
foo.bar:
callback: foo.bar
After running the init command, you'll get the following directory tree (shortened for readability):
indexer
├── hooks
│ ├── foo
│ │ ├── bar.py
│ │ └── __init__.py
│ └── __init__.py
└── sql
└── foo
└── bar
└── .keep
The same rules apply to handler callbacks. Note that the callback field must be a valid Python package name - lowercase letters, underscores, and dots.
Defining models
DipDup uses the Tortoise ORM library to cover database operations. During initialization, DipDup generates a models.py file on the top level of the package that will contain all database models. The name and location of this file cannot be changed.
A typical models.py file looks like the following (example from demo_domains package):
from typing import Optional
from tortoise import fields
from tortoise.fields.relational import ForeignKeyFieldInstance
from dipdup.models import Model
class TLD(Model):
id = fields.CharField(max_length=255, pk=True)
owner = fields.CharField(max_length=36)
class Domain(Model):
id = fields.CharField(max_length=255, pk=True)
tld: ForeignKeyFieldInstance[TLD] = fields.ForeignKeyField('models.TLD', 'domains')
expiry = fields.DatetimeField(null=True)
owner = fields.CharField(max_length=36)
token_id = fields.BigIntField(null=True)
tld_id: Optional[str]
class Record(Model):
id = fields.CharField(max_length=255, pk=True)
domain: ForeignKeyFieldInstance[Domain] = fields.ForeignKeyField('models.Domain', 'records')
address = fields.CharField(max_length=36, null=True)
See the links below to learn how to use this library.
Limitations
Some limitations are applied to model names and fields to avoid ambiguity in GraphQL API.
- Table names must be in
snake_case - Model fields must be in
snake_case - Model fields must differ from table name
Implementing handlers
DipDup generates a separate file with a callback stub for each handler in every index specified in the configuration file.
In the case of the transaction handler, the callback method signature is the following:
from <package>.types.<typename>.parameter.entrypoint_foo import EntryPointFooParameter
from <package>.types.<typename>.parameter.entrypoint_bar import EntryPointBarParameter
from <package>.types.<typename>.storage import TypeNameStorage
async def on_transaction(
ctx: HandlerContext,
entrypoint_foo: Transaction[EntryPointFooParameter, TypeNameStorage],
entrypoint_bar: Transaction[EntryPointBarParameter, TypeNameStorage]
) -> None:
...
where:
entrypoint_foo ... entrypoint_barare items from the according to handler pattern.ctx: HandlerContextprovides useful helpers and contains an internal state (see ).- A
Transactionmodel contains transaction typed parameter and storage, plus other fields.
For the origination case, the handler signature will look similar:
from <package>.types.<typename>.storage import TypeNameStorage
async def on_origination(
ctx: HandlerContext,
origination: Origination[TypeNameStorage],
)
An Origination model contains the origination script, initial storage (typed), amount, delegate, etc.
A Big_map update handler will look like the following:
from <package>.types.<typename>.big_map.<path>_key import PathKey
from <package>.types.<typename>.big_map.<path>_value import PathValue
async def on_update(
ctx: HandlerContext,
update: BigMapDiff[PathKey, PathValue],
)
BigMapDiff contains action (allocate, update, or remove), nullable key and value (typed).
Naming conventions
Python language requires all module and function names in snake case and all class names in pascal case.
A typical imports section of big_map handler callback looks like this:
from <package>.types.<typename>.storage import TypeNameStorage
from <package>.types.<typename>.parameter.<entrypoint> import EntryPointParameter
from <package>.types.<typename>.big_map.<path>_key import PathKey
from <package>.types.<typename>.big_map.<path>_value import PathValue
Here typename is defined in the contract inventory, entrypoint is specified in the handler pattern, and path is in the handler config.
Handling name collisions
Indexing operations of multiple contracts with the same entrypoints can lead to name collisions during code generation. In this case DipDup raises a ConfigurationError and suggests to set alias for each conflicting handler. That applies to operation indexes only. Consider the following index definition, some kind of "chain minting" contract:
kind: operation
handlers:
- callback: on_mint
pattern:
- type: transaction
entrypoint: mint
alias: foo_mint
- type: transaction
entrypoint: mint
alias: bar_mint
The following code will be generated for on_mint callback:
from example.types.foo.parameter.mint import MintParameter as FooMintParameter
from example.types.foo.storage import FooStorage
from example.types.bar.parameter.mint import MintParameter as BarMintParameter
from example.types.bar.storage import BarStorage
async def on_transaction(
ctx: HandlerContext,
foo_mint: Transaction[FooMintParameter, FooStorage],
bar_mint: Transaction[BarMintParameter, BarStorage]
) -> None:
...
You can safely change argument names if you want to.
Templates and variables
Environment variables
DipDup supports compose-style variable expansion with optional default value:
database:
kind: postgres
host: ${POSTGRES_HOST:-localhost}
password: ${POSTGRES_PASSWORD}
You can use environment variables anywhere throughout the configuration file. Consider the following example (absolutely useless but illustrative):
custom:
${FOO}: ${BAR:-bar}
${FIZZ:-fizz}: ${BUZZ}
Running FOO=foo BUZZ=buzz dipdup config export --unsafe will produce the following output:
custom:
fizz: buzz
foo: bar
Use this feature to store sensitive data outside of the configuration file and make your app fully declarative.
Index templates
Templates allow you to reuse index configuration, e.g., for different networks (mainnet/ghostnet) or multiple contracts sharing the same codebase.
templates:
my_template:
kind: operation
datasource: <datasource>
contracts:
- <contract>
handlers:
- callback: callback
pattern:
- destination: <contract>
entrypoint: call
Templates have the same syntax as indexes of all kinds; the only difference is that they additionally support placeholders enabling parameterization:
field: <placeholder>
The template above can be resolved in the following way:
contracts:
some_dex: ...
datasources:
tzkt: ...
indexes:
my_template_instance:
template: my_template
values:
datasource: tzkt_mainnet
contract: some_dex
Any string value wrapped in angle brackets is treated as a placeholder, so make sure there are no collisions with the actual values. You can use a single placeholder multiple times. In contradiction to environment variables, dictionary keys cannot be placeholders.
An index created from a template must have a value for each placeholder; the exception is raised otherwise. These values are available in the handler context as ctx.template_values dictionary.
You can also spawn indexes from templates in runtime. To achieve the same effect as above, you can use the following code:
ctx.add_index(
name='my_template_instance',
template='my_template',
values={
'datasource': 'tzkt_mainnet',
'contract': 'some_dex',
},
)
Indexes
Index — is a primary DipDup entity connecting the inventory and specifying data handling rules.
Each index has a linked TzKT datasource and a set of handlers. Indexes can join multiple contracts considered as a single application. Also, contracts can be used by multiple indexes of any kind, but make sure that data don't overlap. See 2.2. Core concepts → atomicity-and-persistency.
indexes:
contract_operations:
kind: operation
datasource: tzkt_mainnet
handlers:
- callback: on_operation
pattern: ...
Multiple indexes are available for different kinds of blockchain data. Currently, the following options are available:
big_mapeventheadoperationtoken_transfer
Every index is linked to specific datasource from 14.6. datasources config section.
Using templates
Index definitions can be templated to reduce the amount of boilerplate code. To create an index from the template during startup, add an item with the template and values field to the indexes section:
templates:
operation_index_template:
kind: operation
datasource: <datasource>
...
indexes:
template_instance:
template: operation_index_template
values:
datasource: tzkt_mainnet
You can also create indexes from templates later in runtime. See 2.7. Templates and variables page.
Indexing scope
One can optionally specify block levels DipDup has to start and stop indexing at, e.g., there's a new version of the contract, and there's no need to track the old one anymore.
indexes:
my_index:
first_level: 1000000
last_level: 2000000
big_map index
Big maps are lazy structures allowing to access and update only exact keys. Gas costs for these operations doesn't depend on the size of a big map, but you can't iterate over it's keys onchain.
big_map index allows querying only updates of specific big maps. In some cases, it can drastically reduce the amount of data transferred and thus indexing speed compared to fetching all operations.
indexes:
token_big_map_index:
kind: big_map
datasource: tzkt
skip_history: never
handlers:
- callback: on_ledger_update
contract: token
path: data.ledger
- callback: on_token_metadata_update
contract: token
path: token_metadata
Handlers
Each big map handler contains three required fields:
callback— a name of async function with a particular signature; DipDup will search for it in<package>.handlers.<callback>module.contract— big map parent contractpath— path to the big map in the contract storage (use dot as a delimiter)
Index only the current state
When the skip_history field is set to once, DipDup will skip historical changes only on initial sync and switch to regular indexing afterward. When the value is always, DipDup will fetch all big map keys on every restart. Preferrable mode depends on your workload.
All big map diffs DipDup passes to handlers during fast sync have the action field set to BigMapAction.ADD_KEY. Remember that DipDup fetches all keys in this mode, including ones removed from the big map. You can filter them out later by BigMapDiff.data.active field if needed.
event index
Kathmandu Tezos protocol upgrade has introduced contract events, a new way to interact with smart contracts. This index allows indexing events using strictly typed payloads. From the developer's perspective, it's similar to the big_map index with a few differences.
An example below is artificial since no known contracts in mainnet are currently using events.
contract: events_contract
tag: move
- callback: on_roll_event
contract: events_contract
tag: roll
- callback: on_other_event
contract: events_contract
Unlike big maps, contracts may introduce new event tags and payloads at any time, so the index must be updated accordingly.
async def on_move_event(
ctx: HandlerContext,
event: Event[MovePayload],
) -> None:
...
Each contract can have a fallback handler called for all unknown events so you can process untyped data.
async def on_other_event(
ctx: HandlerContext,
event: UnknownEvent,
) -> None:
...
head index
This very simple index provides metadata of the latest block when it's baked. Only realtime data is processed; the synchronization stage is skipped for this index.
spec_version: 1.2
package: demo_head
database:
kind: sqlite
path: demo-head.sqlite3
datasources:
tzkt_mainnet:
kind: tzkt
url: ${TZKT_URL:-https://api.tzkt.io}
indexes:
mainnet_head:
kind: head
datasource: tzkt_mainnet
handlers:
- callback: on_mainnet_head
Head index callback receives HeadBlockData model that contains only basic info; no operations are included. Being useless by itself, this index is helpful for monitoring and cron-like tasks. You can define multiple indexes for each datasource used.
Subscription to the head channel is enabled by default, even if no head indexes are defined. Each time the block is baked, the dipdup_head table is updated per datasource. Use it to ensure that both index datasource and underlying blockchain are up and running.
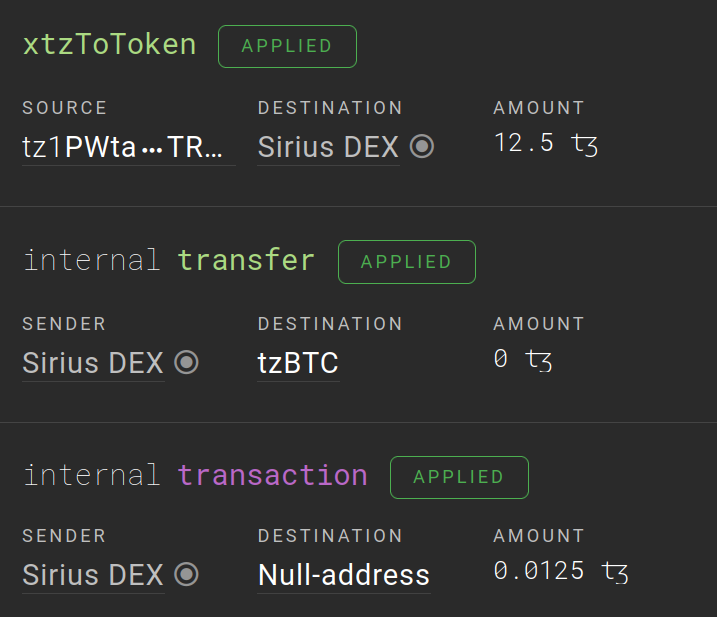
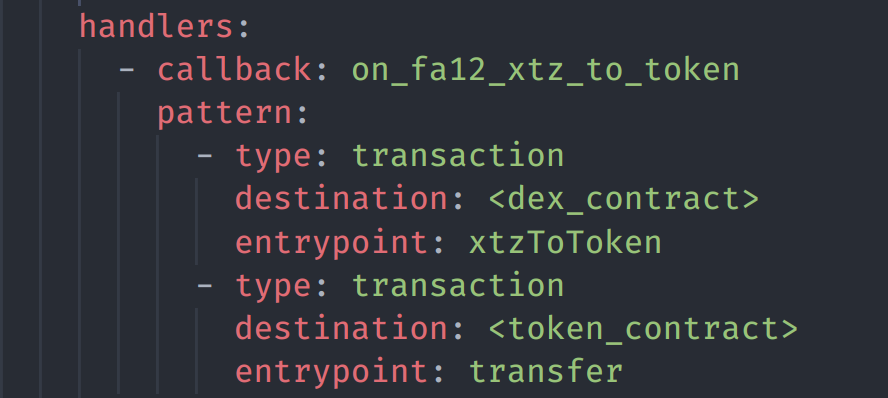
operation index
Operation index allows you to query only operations related to your dapp and match them with handlers by content. A single contract call consists of implicit operation and, optionally, internal operations. For each of them, you can specify a handler that will be called when the operation group matches. As a result, you get something like an event log for your dapp.
Handlers
Each operation handler contains two required fields:
callback— a name of async function with a particular signature; DipDup will search for it in<package>.handlers.<callback>module.pattern— a non-empty list of items that need to be matched.
indexes:
my_index:
kind: operation
datasource: tzkt
contracts:
- some_contract
handlers:
- callback: on_call
pattern:
- destination: some_contract
entrypoint: transfer
You can think of the operation pattern as a regular expression on a sequence of operations (both external and internal) with a global flag enabled (there can be multiple matches). Multiple operation parameters can be used for matching (source, destination, etc.).
You will get slightly different callback argument types depending on whether pattern item is typed or not. If so, DipDup will generate the dataclass for a particular entrypoint/storage, otherwise you will have to handle untyped parameters/storage updates stored in OperationData model.
Matching originations
| name | description | supported | typed |
|---|---|---|---|
originated_contract.address | Origination of exact contract. | ✅ | ✅ |
originated_contract.code_hash | Originations of all contracts having the same code. | ✅ | ✅ |
source.address | Special cases only. This filter is very slow and doesn't support strict typing. Usually, originated_contract.code_hash suits better. | ⚠ | ❌ |
source.code_hash | Currently not supported. | ❌ | ❌ |
similar_to.address | Compatibility alias to originated_contract.code_hash. Can be removed some day. | ➡️ | ➡️ |
similar_to.code_hash | Compatibility alias to originated_contract.code_hash. Can be removed some day. | ➡️ | ➡️ |
Matching transactions
| name | description | supported | typed |
|---|---|---|---|
source.address | Sent by exact address. | ✅ | N/A |
source.code_hash | Sent by any contract having this code hash | ✅ | N/A |
destination.address | Invoked contract address | ✅ | ✅ |
destination.code_hash | Invoked contract code hash | ✅ | ✅ |
destination.entrypoint | Entrypoint called | ✅ | ✅ |
Optional items
Pattern items have optional field to continue matching even if this item is not found. It's usually unnecessary to match the entire operation content; you can skip external/internal calls that are not relevant. However, there is a limitation: optional items cannot be followed by operations ignored by the pattern.
pattern:
# Implicit transaction
- destination: some_contract
entrypoint: mint
# Internal transactions below
- destination: another_contract
entrypoint: transfer
- source: some_contract
type: transaction
Specifying contracts to index
DipDup will try to guess the list of used contracts by handlers' signatures. If you want to specify it explicitly, use contracts field:
indexes:
my_index:
kind: operation
datasource: tzkt
contracts:
- foo
- bar
Specifying operation types
By default, DipDup processes only transactions, but you can enable other operation types you want to process (currently, transaction, origination, and migration are supported).
indexes:
my_index:
kind: operation
datasource: tzkt
types:
- transaction
- origination
- migration
token_transfer index
This index allows indexing token transfers of contracts compatible with FA1.2 or FA2 standards.
spec_version: 1.2
package: demo_token_transfers
database:
kind: sqlite
path: demo-token-transfers.sqlite3
contracts:
tzbtc_mainnet:
address: KT1PWx2mnDueood7fEmfbBDKx1D9BAnnXitn
typename: tzbtc
datasources:
tzkt:
kind: tzkt
url: https://api.tzkt.io
indexes:
tzbtc_holders_mainnet:
kind: token_transfer
datasource: tzkt
handlers:
- callback: on_token_transfer
contract: tzbtc_mainnet
Callback receives TokenTransferData model that optionally contains the transfer sender, receiver, amount, and token metadata.
from decimal import Decimal
from decimal import InvalidOperation
from demo_token_transfers.handlers.on_balance_update import on_balance_update
from dipdup.context import HandlerContext
from dipdup.models import TokenTransferData
async def on_token_transfer(
ctx: HandlerContext,
token_transfer: TokenTransferData,
) -> None:
from_, to = token_transfer.from_address, token_transfer.to_address
if not from_ or not to or from_ == to:
return
try:
amount = Decimal(token_transfer.amount or 0) / (10**8)
except InvalidOperation:
return
if not amount:
return
await on_balance_update(address=from_, balance_update=-amount, timestamp=token_transfer.timestamp)
await on_balance_update(address=to, balance_update=amount, timestamp=token_transfer.timestamp)
GraphQL API
In this section, we assume you use Hasura GraphQL Engine integration to power your API.
Before starting to do client integration, it's good to know the specifics of Hasura GraphQL protocol implementation and the general state of the GQL ecosystem.
Queries
By default, Hasura generates three types of queries for each table in your schema:
- Generic query enabling filters by all columns
- Single item query (by primary key)
- Aggregation query (can be disabled in config)
All the GQL features such as fragments, variables, aliases, directives are supported, as well as batching.
Read more in Hasura docs.
It's important to understand that a GraphQL query is just a POST request with JSON payload, and in some instances, you don't need a complicated library to talk to your backend.
Pagination
By default, Hasura does not restrict the number of rows returned per request, which could lead to abuses and a heavy load on your server. You can set up limits in the configuration file. See 14.7. hasura → limit-number-of-rows. But then, you will face the need to paginate over the items if the response does not fit the limits.
Subscriptions
From Hasura documentation:
Hasura GraphQL engine subscriptions are live queries, i.e., a subscription will return the latest result of the query and not necessarily all the individual events leading up to it.
This feature is essential to avoid complex state management (merging query results and subscription feed). In most scenarios, live queries are what you need to sync the latest changes from the backend.
If the live query has a significant response size that does not fit into the limits, you need one of the following:
- Paginate with offset (which is not convenient)
- Use cursor-based pagination (e.g., by an increasing unique id).
- Narrow down request scope with filtering (e.g., by timestamp or level).
Ultimately you can get "subscriptions" on top of live quires by requesting all the items having ID greater than the maximum existing or all the items with a timestamp greater than now.
Websocket transport
Hasura is compatible with subscriptions-transport-ws library, which is currently deprecated but still used by most clients.
Mutations
The purpose of DipDup is to create indexers, which means you can consistently reproduce the state as long as data sources are accessible. It makes your backend "stateless", meaning tolerant to data loss.
However, you might need to introduce a non-recoverable state and mix indexed and user-generated content in some cases. DipDup allows marking these UGC tables "immune", protecting them from being wiped. In addition to that, you will need to set up Hasura Auth and adjust write permissions for the tables (by default, they are read-only).
Lastly, you will need to execute GQL mutations to modify the state from the client side. Read more about how to do that with Hasura.
Hasura integration
DipDup uses this optional section to configure the Hasura engine to track your tables automatically.
hasura:
url: http://hasura:8080
admin_secret: ${HASURA_ADMIN_SECRET:-changeme}
If you have enabled this integration, DipDup will generate Hasura metadata based on your DB schema and apply it using Metadata API.
Hasura metadata is all about data representation in GraphQL API. The structure of the database itself is managed solely by Tortoise ORM.
Metadata configuration is idempotent: each time you call run or hasura configure command, DipDup queries the existing schema and updates metadata if required. DipDup configures Hasura after reindexing, saves the hash of resulting metadata in the dipdup_schema table, and doesn't touch Hasura until needed.
Database limitations
The current version of Hasura GraphQL Engine treats public and other schemas differently. Table schema.customer becomes schema_customer root field (or schemaCustomer if camel_case option is enabled in DipDup config). Table public.customer becomes customer field, without schema prefix. There's no way to remove this prefix for now. You can track related issue on Hasura's GitHub to know when the situation will change. Starting with 3.0.0-rc1, DipDup enforces public schema name to avoid ambiguity and issues with the GenQL library. You can still use any schema name if Hasura integration is not enabled.
Unauthorized access
DipDup creates user role that allows querying /graphql endpoint without authorization. All tables are set to read-only for this role.
You can limit the maximum number of rows such queries return and also disable aggregation queries automatically generated by Hasura:
hasura:
select_limit: 100
allow_aggregations: False
Note that with limits enabled, you have to use either offset or cursor-based pagination on the client-side.
Convert field names to camel case
For those of you from the JavaScript world, it may be more familiar to use camelCase for variable names instead of snake_case Hasura uses by default. DipDup now allows to convert all fields in metadata to this casing:
hasura:
camel_case: true
Now this example query to hic et nunc demo indexer...
query MyQuery {
hic_et_nunc_token(limit: 1) {
id
creator_id
}
}
...will become this one:
query MyQuery {
hicEtNuncToken(limit: 1) {
id
creatorId
}
}
All fields auto-generated by Hasura will be renamed accordingly: hic_et_nunc_token_by_pk to hicEtNuncTokenByPk, delete_hic_et_nunc_token to deleteHicEtNuncToken and so on. To return to defaults, set camel_case to False and run hasura configure --force.
Remember that "camelcasing" is a separate stage performed after all tables are registered. So during configuration, you can observe fields in snake_case for several seconds even if conversion to camel case is enabled.
Custom Hasura Metadata
There are some cases where you want to apply custom modifications to the Hasura metadata. For example, assume that your database schema has a view that contains data from the main table, in which case you cannot set a foreign key between them. Then you can place files with a .json extension in the hasura directory of your project with the content in Hasura query format, and DipDup will execute them in alphabetical order of file names when the indexing is complete.
The format of the queries can be found in the Metadata API documentation.
Feature flag allow_inconsistent_metadata set in hasura configuration section allows users to modify the behavior of the requests error handling. By default, this value is False.
REST endpoints
Hasura 2.0 introduced the ability to expose arbitrary GraphQL queries as REST endpoints. By default, DipDup will generate GET and POST endpoints to fetch rows by primary key for all tables:
curl http://127.0.0.1:8080/api/rest/hicEtNuncHolder?address=tz1UBZUkXpKGhYsP5KtzDNqLLchwF4uHrGjw
{
"hicEtNuncHolderByPk": {
"address": "tz1UBZUkXpKGhYsP5KtzDNqLLchwF4uHrGjw"
}
}
However, there's a limitation dictated by how Hasura parses HTTP requests: only models with primary keys of basic types (int, string, and so on) can be fetched with GET requests. An attempt to fetch model with BIGINT primary key will lead to the error: Expected bigint for variable id got Number.
A workaround to fetching any model is to send a POST request containing a JSON payload with a single key:
curl -d '{"id": 152}' http://127.0.0.1:8080/api/rest/hicEtNuncToken
{
"hicEtNuncTokenByPk": {
"creatorId": "tz1UBZUkXpKGhYsP5KtzDNqLLchwF4uHrGjw",
"id": 152,
"level": 1365242,
"supply": 1,
"timestamp": "2021-03-01T03:39:21+00:00"
}
}
We hope to get rid of this limitation someday and will let you know as soon as it happens.
Custom endpoints
You can put any number of .graphql files into graphql directory in your project's root, and DipDup will create REST endpoints for each of those queries. Let's say we want to fetch not only a specific token, but also the number of all tokens minted by its creator:
query token_and_mint_count($id: bigint) {
hicEtNuncToken(where: {id: {_eq: $id}}) {
creator {
address
tokens_aggregate {
aggregate {
count
}
}
}
id
level
supply
timestamp
}
}
Save this query as graphql/token_and_mint_count.graphql and run dipdup configure-hasura. Now, this query is available via REST endpoint at http://127.0.0.1:8080/api/rest/token_and_mint_count.
You can disable exposing of REST endpoints in the config:
hasura:
rest: False
GenQL
GenQL is a great library and CLI tool that automatically generates a fully typed SDK with a built-in GQL client. It works flawlessly with Hasura and is recommended for DipDup on the client-side.
Project structure
GenQL CLI generates a ready-to-use package, compiled and prepared to publish to NPM. A typical setup is a mono repository containing several packages, including the auto-generated SDK and your front-end application.
project_root/
├── package.json
└── packages/
├── app/
│ ├── package.json
│ └── src/
└── sdk/
└── package.json
SDK package config
Your minimal package.json file will look like the following:
{
"name": "%PACKAGE_NAME%",
"version": "0.0.1",
"main": "dist/index.js",
"types": "dist/index.d.ts",
"devDependencies": {
"@genql/cli": "^2.6.0"
},
"dependencies": {
"@genql/runtime": "2.6.0",
"graphql": "^15.5.0"
},
"scripts": {
"build": "genql --endpoint %GRAPHQL_ENDPOINT% --output ./dist"
}
}
That's it! Now you only need to install dependencies and execute the build target:
yarn
yarn build
Read more about CLI options available.
Demo
Create a package.json file with
%PACKAGE_NAME%=>metadata-sdk%GRAPHQL_ENDPOINT%=>https://metadata.dipdup.net/v1/graphql
And generate the client:
yarn
yarn build
Then create new file index.ts and paste this query:
import { createClient, everything } from './dist'
const client = createClient()
client.chain.query
.token_metadata({ where: { network: { _eq: 'mainnet' } }})
.get({ ...everything })
.then(res => console.log(res))
We need some additional dependencies to run our sample:
yarn add typescript ts-node
Finally:
npx ts-node index.ts
You should see a list of tokens with metadata attached in your console.
Advanced usage
In this section, you will find information about advanced DipDup features.
Datasources
Datasources are DipDup connectors to various APIs. The table below shows how different datasources can be used.
Index datasource is the one used by DipDup internally to process specific index (set with datasource: ... in config). Currently, it can be only tzkt. Datasources available in context can be accessed in handlers and hooks via ctx.get_<kind>_datasource() methods and used to perform arbitrary requests. Finally, standalone services implement a subset of DipDup datasources and config directives. You can't use services-specific datasources like tezos-node in the main framework, they are here for informational purposes only.
| index | context | mempool service | metadata service | |
|---|---|---|---|---|
tzkt | ✴ | ✅ | ✴ | ✴ |
tezos-node | ❌ | ❌ | ✴ | ❌ |
coinbase | ❌ | ✅ | ❌ | ❌ |
metadata | ❌ | ✅ | ❌ | ❌ |
ipfs | ❌ | ✅ | ❌ | ❌ |
http | ❌ | ✅ | ❌ | ❌ |
✴ required ✅ supported ❌ not supported
TzKT
TzKT provides REST endpoints to query historical data and SignalR (Websocket) subscriptions to get realtime updates. Flexible filters allow you to request only data needed for your application and drastically speed up the indexing process.
datasources:
tzkt_mainnet:
kind: tzkt
url: https://api.tzkt.io
The number of items in each request can be configured with batch_size directive. Affects request number and memory usage.
datasources:
tzkt_mainnet:
http:
...
batch_size: 10000
The rest HTTP tunables are the same as for other datasources.
Also, you can wait for several block confirmations before processing the operations:
datasources:
tzkt_mainnet:
...
buffer_size: 1 # indexing with a single block lag
Since 6.0 chain reorgs are processed automatically, but you may find this feature useful for other cases.
Tezos node
Tezos RPC is a standard interface provided by the Tezos node. This datasource is used solely by mempool and metadata standalone services; you can't use it in regular DipDup indexes.
datasources:
tezos_node_mainnet:
kind: tezos-node
url: https://mainnet-tezos.giganode.io
Coinbase
A connector for Coinbase Pro API. Provides get_candles and get_oracle_data methods. It may be useful in enriching indexes of DeFi contracts with off-chain data.
datasources:
coinbase:
kind: coinbase
Please note that Coinbase can't replace TzKT being an index datasource. But you can access it via ctx.datasources mapping both within handler and job callbacks.
DipDup Metadata
dipdup-metadata is a standalone companion indexer for DipDup written in Go. Configure datasource in the following way:
datasources:
metadata:
kind: metadata
url: https://metadata.dipdup.net
network: mainnet | ithacanet
Then, in your hook or handler code:
datasource = ctx.get_metadata_datasource('metadata')
token_metadata = await datasource.get_token_metadata('KT1...', '0')
IPFS
While working with contract/token metadata, a typical scenario is to fetch it from IPFS. DipDup has a separate datasource to perform such requests via public nodes.
datasources:
ipfs:
kind: ipfs
url: https://ipfs.io/ipfs
You can use this datasource within any callback. Output is either JSON or binary data.
ipfs = ctx.get_ipfs_datasource('ipfs')
file = await ipfs.get('QmdCz7XGkBtd5DFmpDPDN3KFRmpkQHJsDgGiG16cgVbUYu')
assert file[:4].decode()[1:] == 'PDF'
file = await ipfs.get('QmSgSC7geYH3Ae4SpUHy4KutxqNH9ESKBGXoCN4JQdbtEz/package.json')
assert file['name'] == 'json-buffer'
HTTP (generic)
If you need to perform arbitrary requests to APIs not supported by DipDup, use generic HTTP datasource instead of plain aiohttp requests. That way you can use the same features DipDup uses for internal requests: retry with backoff, rate limiting, Prometheus integration etc.
datasources:
my_api:
kind: http
url: https://my_api.local/v1
api = ctx.get_http_datasource('my_api')
response = await api.request(
method='get',
url='hello', # relative to URL in config
weigth=1, # ratelimiter leaky-bucket drops
params={
'foo': 'bar',
},
)
All DipDup datasources are inherited from http, so you can send arbitrary requests with any datasource. Let's say you want to fetch the protocol of the chain you're currently indexing (tzkt datasource doesn't have a separate method for it):
tzkt = ctx.get_tzkt_datasource('tzkt_mainnet')
protocol_json = await tzkt.request(
method='get',
url='v1/protocols/current',
)
assert protocol_json['hash'] == 'PtHangz2aRngywmSRGGvrcTyMbbdpWdpFKuS4uMWxg2RaH9i1qx'
Datasource HTTP connection parameters (ratelimit, retry with backoff, etc.) are applied on every request.
Hooks
Hooks are user-defined callbacks called either from the ctx.fire_hook method or by the job scheduler.
Let's assume we want to calculate some statistics on-demand to avoid blocking an indexer with heavy computations. Add the following lines to the DipDup config:
hooks:
calculate_stats:
callback: calculate_stats
atomic: False
args:
major: bool
depth: int
Here are a couple of things here to pay attention to:
- An
atomicoption defines whether the hook callback will be wrapped in a single SQL transaction or not. If this option is set to true main indexing loop will be blocked until hook execution is complete. Some statements, likeREFRESH MATERIALIZED VIEW, do not require to be wrapped in transactions, so choosing a value of theatomicoption could decrease the time needed to perform initial indexing. - Values of
argsmapping are used as type hints in a signature of a generated callback. We will return to this topic later in this article.
Now it's time to call dipdup init. The following files will be created in the project's root:
├── hooks
│ └── calculate_stats.py
└── sql
└── calculate_stats
└── .keep
Content of the generated callback stub:
from dipdup.context import HookContext
async def calculate_stats(
ctx: HookContext,
major: bool,
depth: int,
) -> None:
await ctx.execute_sql('calculate_stats')
By default, hooks execute SQL scripts from the corresponding subdirectory of sql/. Remove or comment out the execute_sql call to prevent this. This way, both Python and SQL code may be executed in a single hook if needed.
Arguments typechecking
DipDup will ensure that arguments passed to the hooks have the correct types when possible. CallbackTypeError exception will be raised otherwise. Values of an args mapping in a hook config should be either built-in types or __qualname__ of external type like decimal.Decimal. Generic types are not supported: hints like Optional[int] = None will be correctly parsed during codegen but ignored on type checking.
Event hooks
Every DipDup project has multiple event hooks (previously "default hooks"); they fire on system-wide events and, like regular hooks, are not linked to any index. Names of those hooks are reserved; you can't use them in config. It's also impossible to fire them manually or with a job scheduler.
on_restart
This hook executes right before starting indexing. It allows configuring DipDup in runtime based on data from external sources. Datasources are already initialized at execution and available at ctx.datasources. You can, for example, configure logging here or add contracts and indexes in runtime instead of from static config.
on_reindex
This hook fires after the database are re-initialized after reindexing (wipe). Helpful in modifying schema with arbitrary SQL scripts before indexing.
on_synchronized
This hook fires when every active index reaches a realtime state. Here you can clear caches internal caches or do other cleanups.
on_index_rollback
Fires when TzKT datasource has received a chain reorg message which can't be processed by dropping buffered messages (buffer_size option).
Since version 6.0 this hook performs a database-level rollback by default. If it doesn't work for you for some reason remove ctx.rollback call and implement your own rollback logic.
Job scheduler
Jobs are schedules for hooks. In some cases, it may come in handy to have the ability to run some code on schedule. For example, you want to calculate statistics once per hour instead of every time handler gets matched.
Add the following section to the DipDup config:
jobs:
midnight_stats:
hook: calculate_stats
crontab: "0 0 * * *"
args:
major: True
leet_stats:
hook: calculate_stats
interval: 1337 # in seconds
args:
major: False
If you're unfamiliar with the crontab syntax, an online service crontab.guru will help you build the desired expression.
Scheduler configuration
DipDup utilizes apscheduler library to run hooks according to schedules in jobs config section. In the following example, apscheduler will spawn up to three instances of the same job every time the trigger is fired, even if previous runs are in progress:
advanced:
scheduler:
apscheduler.job_defaults.coalesce: True
apscheduler.job_defaults.max_instances: 3
See apscheduler docs for details.
Note that you can't use executors from apscheduler.executors.pool module - ConfigurationError exception will be raised.
Reindexing
In some cases, DipDup can't proceed with indexing without a full wipe. Several reasons trigger reindexing:
| reason | description |
|---|---|
manual | Reindexing triggered manually from callback with ctx.reindex. |
migration | Applied migration requires reindexing. Check release notes before switching between major DipDup versions to be prepared. |
rollback | Reorg message received from TzKT can not be processed. |
config_modified | One of the index configs has been modified. |
schema_modified | Database schema has been modified. Try to avoid manual schema modifications in favor of 5.7. SQL scripts. |
It is possible to configure desirable action on reindexing triggered by a specific reason.
| action | description |
|---|---|
exception (default) | Raise ReindexingRequiredError and quit with error code. The safest option since you can trigger reindexing accidentally, e.g., by a typo in config. Don't forget to set up the correct restart policy when using it with containers. |
wipe | Drop the whole database and start indexing from scratch. Be careful with this option! |
ignore | Ignore the event and continue indexing as usual. It can lead to unexpected side-effects up to data corruption; make sure you know what you are doing. |
To configure actions for each reason, add the following section to the DipDup config:
advanced:
...
reindex:
manual: wipe
migration: exception
rollback: ignore
config_modified: exception
schema_modified: exception
Feature flags
Feature flags set in advanced config section allow users to modify parameters that affect the behavior of the whole framework. Choosing the right combination of flags for an indexer project can improve performance, reduce RAM consumption, or enable useful features.
| flag | description |
|---|---|
crash_reporting | Enable sending crash reports to the Baking Bad team |
early_realtime | Start collecting realtime messages while sync is in progress |
merge_subscriptions | Subscribe to all operations/big map diffs during realtime indexing |
metadata_interface | Enable contract and token metadata interfaces |
postpone_jobs | Do not start the job scheduler until all indexes are synchronized |
skip_version_check | Disable warning about running unstable or out-of-date DipDup version |
Crash reporting
Enables sending crash reports to the Baking Bad team. This is disabled by default. You can inspect crash dumps saved as /tmp/dipdup/crashdumps/XXXXXXX.json before enabling this option.
Early realtime
By default, DipDup enters a sync state twice: before and after establishing a realtime connection. This flag allows collecting realtime messages while the sync is in progress, right after indexes load.
Let's consider two scenarios:
-
Indexing 10 contracts with 10 000 operations each. Initial indexing could take several hours. There is no need to accumulate incoming operations since resync time after establishing a realtime connection depends on the contract number, thus taking a negligible amount of time.
-
Indexing 10 000 contracts with 10 operations each. Both initial sync and resync will take a while. But the number of operations received during this time won't affect RAM consumption much.
If you do not have strict RAM constraints, it's recommended to enable this flag. You'll get faster indexing times and decreased load on TzKT API.
Merge subscriptions
Subscribe to all operations/big map diffs during realtime indexing instead of separate channels. This flag helps to avoid the 10.000 subscription limit of TzKT and speed up processing. The downside is an increased RAM consumption during sync, especially if early_realtime flag is enabled too.
Metadata interface
Without this flag calling ctx.update_contract_metadata and ctx.update_token_metadata methods will have no effect. Corresponding internal tables are created on reindexing in any way.
Postpone jobs
Do not start the job scheduler until all indexes are synchronized. If your jobs perform some calculations that make sense only after the indexer has reached realtime, this toggle can save you some IOPS.
Skip version check
Disables warning about running unstable or out-of-date DipDup version.
Internal environment variables
DipDup uses multiple environment variables internally. They read once on process start and usually do not change during runtime. Some variables modify the framework's behavior, while others are informational.
Please note that they are not currently a part of the public API and can be changed without notice.
| env variable | module path | description |
|---|---|---|
DIPDUP_CI | dipdup.env.CI | Running in GitHub Actions |
DIPDUP_DOCKER | dipdup.env.DOCKER | Running in Docker |
DIPDUP_DOCKER_IMAGE | dipdup.env.DOCKER_IMAGE | Base image used when building Docker image (default, slim or pytezos) |
DIPDUP_NEXT | dipdup.env.NEXT | Enable features thar require schema changes |
DIPDUP_PACKAGE_PATH | dipdup.env.PACKAGE_PATH | Path to the currently used package |
DIPDUP_REPLAY_PATH | dipdup.env.REPLAY_PATH | Path to datasource replay files; used in tests |
DIPDUP_TEST | dipdup.env.TEST | Running in pytest |
DIPDUP_NEXT flag will give you the picture of what's coming in the next major release, but enabling it on existing schema will trigger a reindexing.
SQL scripts
Put your *.sql scripts to <package>/sql. You can run these scripts from any callback with ctx.execute_sql('name'). If name is a directory, each script it contains will be executed.
Scripts are executed without being wrapped with SQL transactions. It's generally a good idea to avoid touching table data in scripts.
SQL scripts are ignored if SQLite is used as a database backend.
By default, an empty sql/<hook_name> directory is generated for every hook in config during init. Remove ctx.execute_sql call from hook callback to avoid executing them.
Event hooks
Scripts from sql/on_restart directory are executed each time you run DipDup. Those scripts may contain CREATE OR REPLACE VIEW or similar non-destructive operations.
Scripts from sql/on_reindex directory are executed after the database schema is created based on the models.py module but before indexing starts. It may be useful to change the database schema in ways that are not supported by the Tortoise ORM, e.g., to create a composite primary key.
Improving performance
This page contains tips that may help to increase indexing speed.
Optimize database schema
Postgres indexes are tables that Postgres can use to speed up data lookup. A database index acts like a pointer to data in a table, just like an index in a printed book. If you look in the index first, you will find the data much quicker than searching the whole book (or — in this case — database).
You should add indexes on columns often appearing in WHERE clauses in your GraphQL queries and subscriptions.
Tortoise ORM uses BTree indexes by default. To set index on a field, add index=True to the field definition:
from dipdup.models import Model
from tortoise import fields
class Trade(Model):
id = fields.BigIntField(pk=True)
amount = fields.BigIntField()
level = fields.BigIntField(index=True)
timestamp = fields.DatetimeField(index=True)
Tune datasources
All datasources now share the same code under the hood to communicate with underlying APIs via HTTP. Configs of all datasources and also Hasura's one can have an optional section http with any number of the following parameters set:
datasources:
tzkt:
kind: tzkt
...
http:
retry_count: 10
retry_sleep: 1
retry_multiplier: 1.2
ratelimit_rate: 100
ratelimit_period: 60
connection_limit: 25
batch_size: 10000
hasura:
url: http://hasura:8080
http:
...
| field | description |
|---|---|
retry_count | Number of retries after request failed before giving up |
retry_sleep | Sleep time between retries |
retry_multiplier | Multiplier for sleep time between retries |
ratelimit_rate | Number of requests per period ("drops" in leaky bucket) |
ratelimit_period | Period for rate limiting in seconds |
connection_limit | Number of simultaneous connections |
connection_timeout | Connection timeout in seconds |
batch_size | Number of items fetched in a single paginated request (for some APIs) |
Each datasource has its defaults. Usually, there's no reason to alter these settings unless you use self-hosted instances of TzKT or other datasource.
By default, DipDup retries failed requests infinitely, exponentially increasing the delay between attempts. Set retry_count parameter to limit the number of attempts.
batch_size parameter is TzKT-specific. By default, DipDup limit requests to 10000 items, the maximum value allowed on public instances provided by Baking Bad. Decreasing this value will reduce the time required for TzKT to process a single request and thus reduce the load. By reducing the connection_limit parameter, you can achieve the same effect (limited to synchronizing multiple indexes concurrently).
See 12.4. datasources for details.
Use TimescaleDB for time-series
This page or paragraph is yet to be written. Come back later.
DipDup is fully compatible with TimescaleDB. Try its "continuous aggregates" feature, especially if dealing with market data like DEX quotes.
Cache commonly used models
If your indexer contains models having few fields and used primarily on relations, you can cache such models during synchronization.
Example code:
class Trader(Model):
address = fields.CharField(36, pk=True)
class TraderCache:
def __init__(self, size: int = 1000) -> None:
self._size = size
self._traders: OrderedDict[str, Trader] = OrderedDict()
async def get(self, address: str) -> Trader:
if address not in self._traders:
# NOTE: Already created on origination
self._traders[address], _ = await Trader.get_or_create(address=address)
if len(self._traders) > self._size:
self._traders.popitem(last=False)
return self._traders[address]
trader_cache = TraderCache()
Use trader_cache.get in handlers. After sync is complete, you can clear this cache to free some RAM:
async def on_synchronized(
ctx: HookContext,
) -> None:
...
models.trader_cache.clear()
Perform heavy computations in separate processes
It's impossible to use apscheduler pool executors with hooks because HookContext is not pickle-serializable. So, they are forbidden now in advanced.scheduler config. However, thread/process pools can come in handy in many situations, and it would be nice to have them in DipDup context. For now, I can suggest implementing custom commands as a workaround to perform any resource-hungry tasks within them. Put the following code in <project>/cli.py:
from contextlib import AsyncExitStack
import asyncclick as click
from dipdup.cli import cli, cli_wrapper
from dipdup.config import DipDupConfig
from dipdup.context import DipDupContext
from dipdup.utils.database import tortoise_wrapper
@cli.command(help='Run heavy calculations')
@click.pass_context
@cli_wrapper
async def do_something_heavy(ctx):
config: DipDupConfig = ctx.obj.config
url = config.database.connection_string
models = f'{config.package}.models'
async with AsyncExitStack() as stack:
await stack.enter_async_context(tortoise_wrapper(url, models))
...
if __name__ == '__main__':
cli(prog_name='dipdup', standalone_mode=False)
Then use python -m <project>.cli instead of dipdup as an entrypoint. Now you can call do-something-heavy like any other dipdup command. dipdup.cli:cli group handles arguments and config parsing, graceful shutdown, and other boilerplate. The rest is on you; use dipdup.dipdup:DipDup.run as a reference. And keep in mind that Tortoise ORM is not thread-safe. I aim to implement ctx.pool_apply and ctx.pool_map methods to execute code in pools with magic within existing DipDup hooks, but no ETA yet.
Callback context (ctx)
An instance of the HandlerContext class is passed to every handler providing a set of helper methods and read-only properties.
Reference
- class dipdup.context.DipDupContext(datasources, config, callbacks, transactions)¶
Common execution context for handler and hook callbacks.
- Parameters:
datasources (dict[str, dipdup.datasources.datasource.Datasource]) – Mapping of available datasources
config (DipDupConfig) – DipDup configuration
logger – Context-aware logger instance
callbacks (CallbackManager) –
transactions (TransactionManager) –
- class dipdup.context.HandlerContext(datasources, config, callbacks, transactions, logger, handler_config, datasource)¶
Execution context of handler callbacks.
- Parameters:
handler_config (HandlerConfig) – Configuration of the current handler
datasource (TzktDatasource) – Index datasource instance
datasources (dict[str, dipdup.datasources.datasource.Datasource]) –
config (DipDupConfig) –
callbacks (CallbackManager) –
transactions (TransactionManager) –
logger (FormattedLogger) –
- class dipdup.context.HookContext(datasources, config, callbacks, transactions, logger, hook_config)¶
Execution context of hook callbacks.
- Parameters:
hook_config (HookConfig) – Configuration of the current hook
datasources (dict[str, dipdup.datasources.datasource.Datasource]) –
config (DipDupConfig) –
callbacks (CallbackManager) –
transactions (TransactionManager) –
logger (FormattedLogger) –
- async DipDupContext.add_contract(name, address=None, typename=None, code_hash=None)¶
Adds contract to the inventory.
- Parameters:
name (str) – Contract name
address (str | None) – Contract address
typename (str | None) – Alias for the contract script
code_hash (str | int | None) – Contract code hash
- Return type:
None
- async DipDupContext.add_index(name, template, values, first_level=0, last_level=0, state=None)¶
Adds a new contract to the inventory.
- Parameters:
name (str) – Index name
template (str) – Index template to use
values (dict[str, Any]) – Mapping of values to fill template with
first_level (int) –
last_level (int) –
state (Index | None) –
- Return type:
None
- async DipDupContext.execute_sql(name, *args, **kwargs)¶
Executes SQL script(s) with given name.
If the name path is a directory, all .sql scripts within it will be executed in alphabetical order.
- Parameters:
name (str) – File or directory within project’s sql directory
args (Any) –
kwargs (Any) –
- Return type:
None
- async DipDupContext.execute_sql_query(name, *args)¶
Executes SQL query with given name
- Parameters:
name (str) – SQL query name within <project>/sql directory
args (Any) –
- Return type:
Any
- async DipDupContext.fire_hook(name, fmt=None, wait=True, *args, **kwargs)¶
Fire hook with given name and arguments.
- Parameters:
name (str) – Hook name
fmt (str | None) – Format string for ctx.logger messages
wait (bool) – Wait for hook to finish or fire and forget
args (Any) –
kwargs (Any) –
- Return type:
None
- DipDupContext.get_coinbase_datasource(name)¶
Get coinbase datasource by name
- Parameters:
name (str) –
- Return type:
CoinbaseDatasource
- DipDupContext.get_http_datasource(name)¶
Get http datasource by name
- Parameters:
name (str) –
- Return type:
HttpDatasource
- DipDupContext.get_ipfs_datasource(name)¶
Get ipfs datasource by name
- Parameters:
name (str) –
- Return type:
IpfsDatasource
- DipDupContext.get_metadata_datasource(name)¶
Get metadata datasource by name
- Parameters:
name (str) –
- Return type:
MetadataDatasource
- DipDupContext.get_tzkt_datasource(name)¶
Get tzkt datasource by name
- Parameters:
name (str) –
- Return type:
TzktDatasource
- async DipDupContext.reindex(reason=None, **context)¶
Drops the entire database and starts the indexing process from scratch.
- Parameters:
reason (str | ReindexingReason | None) – Reason for reindexing in free-form string
context (Any) – Additional information to include in exception message
- Return type:
None
- async DipDupContext.restart()¶
Restart process and continue indexing.
- Return type:
None
- async DipDupContext.update_contract_metadata(network, address, metadata)¶
Inserts or updates corresponding rows in the internal dipdup_contract_metadata table to provide a generic metadata interface (see docs).
- Parameters:
network (str) – Network name (e.g. mainnet)
address (str) – Contract address
metadata (dict[str, Any]) – Contract metadata to insert/update
- Return type:
None
- async DipDupContext.update_token_metadata(network, address, token_id, metadata)¶
Inserts or updates corresponding rows in the internal dipdup_token_metadata table to provide a generic metadata interface (see docs).
- Parameters:
network (str) – Network name (e.g. mainnet)
address (str) – Contract address
token_id (str) – Token ID
metadata (dict[str, Any]) – Token metadata to insert/update
- Return type:
None
- async HookContext.rollback(index, from_level, to_level)¶
Rollback index to a given level reverting all changes made since that level.
- Parameters:
index (str) – Index name
from_level (int) – Level to rollback from
to_level (int) – Level to rollback to
- Return type:
None
Internal models
This page describes the internal models used by DipDup. You shouldn't modify data in these models directly.
| model | table | description |
|---|---|---|
Model | N/A | Base class for all models in DipDup project. Provides advanced transaction management. |
Schema | dipdup_schema | Hash of database schema to detect changes that require reindexing. |
Head | dipdup_head | The latest block received by a datasource from a WebSocket connection. |
Index | dipdup_index | Indexing status, level of the latest processed block, template, and template values if applicable. |
Contract | dipdup_contract | Nothing useful for us humans. It helps DipDup to keep track of dynamically spawned contracts. |
ModelUpdate | dipdup_model_update | Service table to store model diffs for database rollback. |
ContractMetadata | dipdup_contract_metadata | See 5.12. Metadata interface |
TokenMetadata | dipdup_token_metadata | See 5.12. Metadata interface |
With the help of these tables, you can set up monitoring of DipDup deployment to know when something goes wrong:
-- This query will return time since the latest block was received by a datasource.
SELECT NOW() - timestamp FROM dipdup_head;
Index factories
This page or paragraph is yet to be written. Come back later.
DipDup allows creating new indexes in runtime. To begin with, you need to define index templates in the top-level templates section of the config. Then call ctx.add_contract and ctx.add_index methods from any user callback.
The most common way to spawn indexes is to create an index that tracks the originations of contracts with similar code or originated by a specific contract. A minimal example looks like this:
contracts:
registry:
address: KT19CF3KKrvdW77ttFomCuin2k4uAVkryYqh
indexes:
factory:
kind: operation
datasource: tzkt
types:
- origination
handlers:
- callback: on_factory_origination
pattern:
- type: origination
similar_to: registry
Another solution is to implement custom logic in on_restart hook (see 5.3. Event hooks → on_restart)
Metadata Interface
When issuing a token on Tezos blockchain, there is an important yet not enough covered aspect related to how various ecosystem applications (wallets, explorers, marketplaces, and others) will display and interact with it. It's about token metadata, stored wholly or partially on-chain but intended for off-chain use only.
Token metadata standards
There are several standards regulating the metadata file format and the way it can be stored and exposed to consumers:
- TZIP-21 | Rich Metadata — describes a metadata schema and standards for contracts and tokens
- TZIP-12 | FA2.0 — a standard for a unified token contract interface, includes an article about how to store and encode token metadata
- TZIP-7 | FA1.2 — single asset token standard; reuses the token metadata approach from FA2.0
Keeping aside the metadata schema, let's focus on which approaches for storing are currently standardized, their pros and cons, and what to do if any of the options available do not fit your case.
Basic: on-chain links / off-chain storage
The most straightforward approach is to store everything in the contract storage, especially if it's just the basic fields (name, symbol, decimals):
storage
└── token_metadata [big_map]
└── 0
├── token_id: 0
└── token_info
├── name: ""
├── symbol: ""
└── decimals: ""
But typically, you want to store more like a token thumbnail icon, and it is no longer feasible to keep such large data on-chain (because you pay gas for every byte stored).
Then you can put large files somewhere off-chain (e.g., IPFS) and store just links:
storage
└── token_metadata [big_map]
└── 0
├── token_id: 0
└── token_info
├── ...
└── thumbnailUri: "ipfs://"
This approach is still costly, but sometimes (in rare cases), you need to have access to the metadata from the contract (example: Dogami).
We can go further and put the entire token info structure to IPFS:
storage
└── token_metadata [big_map]
└── 0
├── token_id: 0
└── token_info
└── "": "ipfs://"
It is the most common case right now (example: HEN).
The main advantage of the basic approach is that all the changes applied to token metadata will result in big map diffs that are easily traceable by indexers. Even if you decide to replace the off-chain file, it will cause the IPFS link to change. In the case of HTTP links, indexers cannot detect the content change; thus, token metadata won't be updated.
Custom: off-chain view
The second approach presented in the TZIP-12 spec was intended to cover the cases when there's a need in reusing the same token info or when it's not possible to expose the %token_metadata big map in the standard form. Instead, it's offered to execute a special Michelson script against the contract storage and treat the result as the token info for a particular token (requested). The tricky part is that the script code itself is typically stored off-chain, and the whole algorithm would look like this:
- Try to fetch the empty string key of the
%metadatabig map to retrieve the TZIP-16 file location - Resolve the TZIP-16 file (typically from IPFS) — it should contain the off-chain view body
- Fetch the current contract storage
- Build arguments for the off-chain view
token_metadatausing fetched storage and - Execute the script using Tezos node RPC
Although this approach is more or less viable for wallets (when you need to fetch metadata for a relatively small amount of tokens), it becomes very inefficient for indexers dealing with millions of tokens:
- After every contract origination, one has to try to fetch the views (even if there aren't any) — it means synchronous fetching, which can take seconds in the case of IPFS
- Executing a Michelson script is currently only* possible via Tezos node, and it's quite a heavy call (setting up the VM and contract context takes time)
- There's no clear way to detect new token metadata addition or change — that is actually the most critical one; you never know for sure when to call the view
Off-chain view approach is not supported by TzKT indexer, and we strongly recommend not to use it, especially for contracts that can issue multiple tokens.
DipDup-based solution
The alternative we offer for the very non-standard cases is using our selective indexing framework for custom token metadata retrieval and then feeding it back to the TzKT indexer, which essentially acts as a metadata aggregator. Note that while this can seem like a circular dependency, it's resolved on the interface level: all custom DipDup metadata indexers should expose specific GraphQL tables with certain fields:
query MyQuery {
token_metadata() {
metadata // TZIP-21 JSON
network // mainnet or <protocol>net
contract // token contract address
token_id // token ID in the scope of the contract
update_id // integer cursor used for pagination
}
}
DipDup handles table management for you and exposes a context-level helper.
Tezos Domains example:
await ctx.update_token_metadata(
network=ctx.datasource.network,
address=store_records.data.contract_address,
token_id=token_id,
metadata={
'name': record_name,
'symbol': 'TD',
'decimals': '0',
'isBooleanAmount': True,
'domainData': decode_domain_data(store_records.value.data)
},
)
TzKT can be configured to subscribe to one or multiple DipDup metadata sources, currently we use in production:
- Generic TZIP-16/TZIP-12 metadata indexer Github | Playground
- Tezos Domains metadata indexer Github | Playground
- Ubisoft Quartz metadata indexer Github | Playground

Deployment and operations
This section contains recipes to deploy and maintain DipDup instances.
Database engines
DipDup officially supports the following databases: SQLite, PostgreSQL, TimescaleDB. This table will help you choose a database engine that mostly suits your needs.
| SQLite | PostgreSQL | TimescaleDB | |
|---|---|---|---|
| Supported versions | latest | 13, 14 | pg13, pg14 |
| Best application | development | general usage | working with timeseries |
| SQL scripts | ✅ | ✅ | ✅ |
| Immune tables | ❌ | ✅ | ✅ |
| Hasura integration | ❌ | ✅ | ✅ |
By default DipDup uses in-memory SQLite database that destroys after the process exits.
While sometimes it's convenient to use one database engine for development and another one for production, be careful with specific column types that behave differently in various engines. However, Tortoise ORM mostly hides these differences.
Running in Docker
Base images
-pytezos tag is deprecated and will be removed in the next major release. Also -slim images will be based on Ubuntu instead of Alpine.
DipDup provides multiple prebuilt images for different environments hosted on Docker Hub. Choose the one according to your needs from the table below.
| default | pytezos | slim | |
|---|---|---|---|
| base image | python:3.10-slim | python:3.10-slim | python:3.10-alpine |
| platforms | amd64, arm64 | amd64, arm64 | amd64, arm64 |
| latest tag | 6 | 6-pytezos | 6-slim |
| image size | 376M | 496M | 97M |
dipdup init command | ✅ | ✅ | ❌ |
git and poetry included | ✅ | ✅ | ❌ |
| PyTezos included | ❌ | ✅ | ❌ |
The default DipDup image is suitable for development and testing. It also includes some tools to make package management easier. If unsure, use this image.
-slim image based on Alpine Linux, thus is much smaller than the default one. Also, it doesn't include codegen functionality (init command, unlikely to be useful in production). This image will eventually become the default one.
-pytezos image includes pre-installed PyTezos library. DipDup doesn't provide any further PyTezos integration. Having some patience, you can build a trading robot or something like that using this image.
Nightly builds (ghcr.io)
In addition to Docker Hub we also publish images on GitHub Container Registry. Builds are triggered on push to any branch for developers' convenience, but only Alpine images are published. Do not use nightlies in production!
# Latest image for `aux/arm64` branch
FROM ghcr.io/dipdup-io/dipdup:aux-arm64
Writing Dockerfile
Start with creating .dockerignore for your project if it's missing.
# Ignore all
*
# Add build files
!Makefile
!pyproject.toml
!poetry.lock
!requirements**
!README.md
# Add code
!src
# Add configs
!*.yml
# Ignore caches
**/.mypy_cache
**/.pytest_cache
**/__pycache__
A typical Dockerfile looks like this:
FROM dipdup/dipdup:6
# FROM dipdup/dipdup:6-pytezos
# FROM dipdup/dipdup:6-slim
# Optional: install additional dependencies using poetry
# COPY pyproject.toml poetry.lock .
# RUN install_dependencies
# Optional: install additional dependencies using pip
# COPY requirements.txt .
# RUN install_dependencies requirements.txt
COPY . .
Note that Poetry integration is not available in the slim image.
Deploying with docker-compose
Make sure you have docker run and docker-compose installed.
Example docker-compose.yml file:
version: "3.8"
services:
dipdup:
build: .
depends_on:
- db
command: ["-c", "dipdup.yml", "-c", "dipdup.prod.yml", "run"]
restart: always
environment:
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD:-changeme}
- ADMIN_SECRET=${ADMIN_SECRET:-changeme}
ports:
- 127.0.0.1:9000:9000
db:
image: postgres:14
ports:
- 127.0.0.1:5432:5432
volumes:
- db:/var/lib/postgresql/data
restart: always
environment:
- POSTGRES_USER=dipdup
- POSTGRES_DB=dipdup
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD:-changeme}
healthcheck:
test: ["CMD-SHELL", "pg_isready -U dipdup"]
interval: 10s
timeout: 5s
retries: 5
hasura:
image: hasura/graphql-engine:v2.28.0
ports:
- 127.0.0.1:8080:8080
depends_on:
- db
restart: always
environment:
- HASURA_GRAPHQL_DATABASE_URL=postgres://dipdup:${POSTGRES_PASSWORD:-changeme}@db:5432
- HASURA_GRAPHQL_ENABLE_CONSOLE=true
- HASURA_GRAPHQL_DEV_MODE=true
- HASURA_GRAPHQL_ENABLED_LOG_TYPES=startup, http-log, webhook-log, websocket-log, query-log
- HASURA_GRAPHQL_ADMIN_SECRET=${HASURA_SECRET:-changeme}
- HASURA_GRAPHQL_UNAUTHORIZED_ROLE=user
- HASURA_GRAPHQL_STRINGIFY_NUMERIC_TYPES=true
volumes:
db:
Environment variables are expanded in the DipDup config file; Postgres password and Hasura secret are forwarded in this example.
Create a separate dipdup.<environment>.yml file for this stack:
database:
kind: postgres
host: db
port: 5432
user: ${POSTGRES_USER:-dipdup}
password: ${POSTGRES_PASSWORD:-changeme}
database: ${POSTGRES_DB:-dipdup}
hasura:
url: http://hasura:8080
admin_secret: ${HASURA_SECRET:-changeme}
allow_aggregations: false
camel_case: true
sentry:
dsn: ${SENTRY_DSN:-""}
environment: ${SENTRY_ENVIRONMENT:-prod}
prometheus:
host: 0.0.0.0
advanced:
early_realtime: True
crash_reporting: False
Note the hostnames (resolved in the docker network) and environment variables (expanded by DipDup).
Build and run the containers:
docker-compose up -d --build
Try lazydocker tool to manage Docker containers interactively.
Deploying with Docker Swarm
This page or paragraph is yet to be written. Come back later.
Example stack:
version: "3.8"
services:
dipdup:
image: ${DOCKER_REGISTRY:-ghcr.io}/dipdup-io/dipdup:${TAG:-master}
depends_on:
- db
- hasura
command: ["-c", "dipdup.yml", "-c", "dipdup.prod.yml", "run"]
environment:
- "POSTGRES_USER=dipdup"
- "POSTGRES_PASSWORD=changeme"
- "POSTGRES_DB=dipdup"
- "HASURA_SECRET=changeme"
networks:
- dipdup-private
- prometheus-private
deploy:
mode: replicated
replicas: ${INDEXER_ENABLED:-1}
labels:
- prometheus-job=${SERVICE}
- prometheus-port=8000
placement: &placement
constraints:
- node.labels.${SERVICE} == true
logging: &logging
driver: "json-file"
options:
max-size: "10m"
max-file: "10"
tag: "\{\{.Name\}\}.\{\{.ImageID\}\}"
db:
image: postgres:14
volumes:
- db:/var/lib/postgresql/data
environment:
- POSTGRES_USER=dipdup
- POSTGRES_DB=dipdup
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD:-changeme}
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 10s
timeout: 5s
retries: 5
networks:
- dipdup-private
deploy:
mode: replicated
replicas: 1
placement: *placement
logging: *logging
hasura:
image: hasura/graphql-engine:v2.28.0
depends_on:
- db
environment:
- HASURA_GRAPHQL_DATABASE_URL=postgres://dipdup:${POSTGRES_PASSWORD:-changeme}@db:5432
- HASURA_GRAPHQL_ENABLE_CONSOLE=true
- HASURA_GRAPHQL_DEV_MODE=false
- HASURA_GRAPHQL_ENABLED_LOG_TYPES=startup, http-log, websocket-log, query-log
- HASURA_GRAPHQL_LOG_LEVEL=warn
- HASURA_GRAPHQL_ENABLE_TELEMETRY=false
- HASURA_GRAPHQL_ADMIN_SECRET=${HASURA_SECRET}
- HASURA_GRAPHQL_UNAUTHORIZED_ROLE=user
- HASURA_GRAPHQL_STRINGIFY_NUMERIC_TYPES=true
networks:
- dipdup-private
- traefik-public
deploy:
mode: replicated
replicas: 1
labels:
- traefik.enable=true
- traefik.http.services.${SERVICE}.loadbalancer.server.port=8080
- "traefik.http.routers.${SERVICE}.rule=Host(`${HOST}`) && (PathPrefix(`/v1/graphql`) || PathPrefix(`/api/rest`))"
- traefik.http.routers.${SERVICE}.entrypoints=http,${INGRESS:-ingress}
- "traefik.http.routers.${SERVICE}-console.rule=Host(`${SERVICE}.${SWARM_ROOT_DOMAIN}`)"
- traefik.http.routers.${SERVICE}-console.entrypoints=https
- traefik.http.middlewares.${SERVICE}-console.headers.customrequestheaders.X-Hasura-Admin-Secret=${HASURA_SECRET}
- traefik.http.routers.${SERVICE}-console.middlewares=authelia@docker,${SERVICE}-console
placement: *placement
logging: *logging
volumes:
db:
networks:
dipdup-private:
traefik-public:
external: true
prometheus-private:
external: true
Sentry integration
Sentry is an error tracking software that can be used either as a service or on-premise. It dramatically improves the troubleshooting experience and requires nearly zero configuration. To start catching exceptions with Sentry in your project, add the following section in dipdup.yml config:
sentry:
dsn: https://...
environment: dev
debug: False
You can obtain Sentry DSN from the web interface at Settings -> Projects -> <project_name> -> Client Keys (DSN). The cool thing is that if you catch an exception and suspect there's a bug in DipDup, you can share this event with us using a public link (created at Share menu).
Prometheus integration
DipDup provides basic integration with the Prometheus monitoring system by exposing some metrics.
When running DipDup in Docker make sure that the Prometheus instance is in the same network.
Available metrics
The following metrics are exposed under dipdup namespace:
| metric name | description |
|---|---|
dipdup_indexes_total | Number of indexes in operation by status |
dipdup_index_level_sync_duration_seconds | Duration of indexing a single level |
dipdup_index_level_realtime_duration_seconds | Duration of last index syncronization |
dipdup_index_total_sync_duration_seconds | Duration of the last index syncronization |
dipdup_index_total_realtime_duration_seconds | Duration of the last index realtime syncronization |
dipdup_index_levels_to_sync_total | Number of levels to reach synced state |
dipdup_index_levels_to_realtime_total | Number of levels to reach realtime state |
dipdup_index_handlers_matched_total | Index total hits |
dipdup_datasource_head_updated_timestamp | Timestamp of the last head update |
dipdup_datasource_rollbacks_total | Number of rollbacks |
dipdup_http_errors_total | Number of http errors |
dipdup_callback_duration_seconds | Duration of callback execution |
You can also query 5.10. Internal models for monitoring purposes.
Logging
To control the number of logs DipDup produces, set the logging field in config:
logging: default|verbose|quiet
If you need more fined tuning, perform it in the on_restart hook:
import logging
async def on_restart(
ctx: HookContext,
) -> None:
logging.getLogger('some_logger').setLevel('DEBUG')
Backup and restore
DipDup has no built-in functionality to backup and restore database at the moment. Good news is that DipDup indexes are fully atomic. That means you can perform backup with regular psql/pgdump regardless of the DipDup state.
This page contains several recipes for backup/restore.
Scheduled backup to S3
This example is for Swarm deployments. We use this solution to backup our services in production. Adapt it to your needs if needed.
version: "3.8"
services:
indexer:
...
db:
...
hasura:
...
backuper:
image: ghcr.io/dipdup-io/postgres-s3-backup:master
environment:
- S3_ENDPOINT=${S3_ENDPOINT:-https://fra1.digitaloceanspaces.com}
- S3_ACCESS_KEY_ID=${S3_ACCESS_KEY_ID}
- S3_SECRET_ACCESS_KEY=${S3_SECRET_ACCESS_KEY}
- S3_BUCKET=dipdup
- S3_PATH=dipdup
- S3_FILENAME=${SERVICE}-postgres
- PG_BACKUP_FILE=${PG_BACKUP_FILE}
- PG_BACKUP_ACTION=${PG_BACKUP_ACTION:-dump}
- PG_RESTORE_JOBS=${PG_RESTORE_JOBS:-8}
- POSTGRES_USER=${POSTGRES_USER:-dipdup}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD:-changeme}
- POSTGRES_DB=${POSTGRES_DB:-dipdup}
- POSTGRES_HOST=${POSTGRES_HOST:-db}
- HEARTBEAT_URI=${HEARTBEAT_URI}
- SCHEDULE=${SCHEDULE}
deploy:
mode: replicated
replicas: ${BACKUP_ENABLED:-0}
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 5
window: 120s
placement: *placement
networks:
- internal
logging: *logging
Automatic restore on rollback
This awesome code was contributed by @852Kerfunkle, author of tz1and project.
<project>/backups.py
...
def backup(level: int, database_config: PostgresDatabaseConfig):
...
with open('backup.sql', 'wb') as f:
try:
err_buf = StringIO()
pg_dump('-d', f'postgresql://{database_config.user}:{database_config.password}@{database_config.host}:{database_config.port}/{database_config.database}', '--clean',
'-n', database_config.schema_name, _out=f, _err=err_buf) #, '-E', 'UTF8'
except ErrorReturnCode:
err = err_buf.getvalue()
_logger.error(f'Database backup failed: {err}')
def restore(level: int, database_config: PostgresDatabaseConfig):
...
with open('backup.sql', 'r') as f:
try:
err_buf = StringIO()
psql('-d', f'postgresql://{database_config.user}:{database_config.password}@{database_config.host}:{database_config.port}/{database_config.database}',
'-n', database_config.schema_name, _in=f, _err=err_buf)
except ErrorReturnCode:
err = err_buf.getvalue()
_logger.error(f'Database restore failed: {err}')
raise Exception("Failed to restore")
def get_available_backups():
...
def delete_old_backups():
...
<project>/hooks/on_index_rollback.py
...
async def on_index_rollback(
ctx: HookContext,
index: Index, # type: ignore[type-arg]
from_level: int,
to_level: int,
) -> None:
await ctx.execute_sql('on_index_rollback')
database_config: Union[SqliteDatabaseConfig, PostgresDatabaseConfig] = ctx.config.database
# if not a postgres db, reindex.
if database_config.kind != "postgres":
await ctx.reindex(ReindexingReason.ROLLBACK)
available_levels = backups.get_available_backups()
# if no backups available, reindex
if not available_levels:
await ctx.reindex(ReindexingReason.ROLLBACK)
# find the right level. ie the on that's closest to to_level
chosen_level = 0
for level in available_levels:
if level <= to_level and level > chosen_level:
chosen_level = level
# try to restore or reindex
try:
backups.restore(chosen_level, database_config)
await ctx.restart()
except Exception:
await ctx.reindex(ReindexingReason.ROLLBACK)
<project>/hooks/run_backups.py
...
async def run_backups(
ctx: HookContext,
) -> None:
database_config: Union[SqliteDatabaseConfig, PostgresDatabaseConfig] = ctx.config.database
if database_config.kind != "postgres":
return
level = ctx.get_tzkt_datasource("tzkt_mainnet")._level.get(MessageType.head)
if level is None:
return
backups.backup(level, database_config)
backups.delete_old_backups()
<project>/hooks/simulate_reorg.py
...
async def simulate_reorg(
ctx: HookContext
) -> None:
level = ctx.get_tzkt_datasource("tzkt_mainnet")._level.get(MessageType.head)
if level:
await ctx.fire_hook(
"on_index_rollback",
wait=True
index=None, # type: ignore[arg-type]
from_level=level,
to_level=level - 2,
)
Monitoring
To perform up-to-date and freshness checks, DipDup provides a standard REST endpoint you can use together with Betteruptime or similar services that can search for a keyword in the response.
This check says that DipDup is not stuck and keeps receiving new data (the last known block timestamp is not older than three minutes from now). Note that this is not enough to ensure everything works as expected. But it can at least cover the cases when datasource API is down or your indexer has crashed.
URI format
https://<your-indexer-host>/api/rest/dipdup_head_status?name=<datasource-uri>
If you have camel case enabled in the Hasura config:
https://<your-indexer-host>/api/rest/dipdupHeadStatus?name=<datasource-uri>
For example:
- https://domains.dipdup.net/api/rest/dipdup_head_status?name=https://api.tzkt.io
- https://juster.dipdup.net/api/rest/dipdupHeadStatus?name=https://api.tzkt.io
Response
If the (latest block) head subscription state was updated less than three minutes ago, everything is OK:
{
"dipdup_head_status": [
{
"status": "OK"
}
]
}
Otherwise, the state is considered OUTDATED:
{
"dipdup_head_status": [
{
"status": "OUTDATED"
}
]
}
Custom checks
The default check looks like the following:
CREATE
OR REPLACE VIEW dipdup_head_status AS
SELECT
name,
CASE
WHEN timestamp < NOW() - interval '3 minutes' THEN 'OUTDATED'
ELSE 'OK'
END AS status
FROM
dipdup_head;
You can also create your custom alert endpoints using SQL views and functions and then convert them to Hasura REST endpoints.
F.A.Q
How to index the different contracts that share the same interface?
Multiple contracts can provide the same interface (like FA1.2 and FA2 standard tokens) but have a different storage structure. If you try to use the same typename for them, indexing will fail. However, you can modify typeclasses manually. Modify types/<typename>/storage.py file and comment out unique fields that are not important for your index:
# dipdup: ignore
...
class ContractStorage(BaseModel):
class Config:
extra = Extra.ignore
common_ledger: Dict[str, str]
# unique_field_foo: str
# unique_field_bar: str
Note the # dipdup: ignore comment on the first line. It tells DipDup not to overwrite this file on init --overwrite-types command.
Don't forget Extra.ignore Pydantic hint, otherwise, storage deserialization will fail.
What is the correct way to process off-chain data?
DipDup provides convenient helpers to process off-chain data like market quotes or IPFS metadata. Follow the tips below to use them most efficiently.
- Do not perform off-chain requests in handers until necessary. Use hooks instead, enriching indexed data on-demand.
- Use generic
httpdatasources for external APIs instead of plainaiohttprequests. This way you can use the same features DipDup uses for internal requests: retry with backoff, rate limiting, Prometheus integration etc. - Database tables that store off-chain data can be marked as immune, preventing them from being removed on reindexing.
One of my indexes depends on another one's indexed data. How to process them in a specific order?
Indexes of all kinds are fully independent. They are processed in parallel, have their message queues, and don't share any state. It is one of the essential DipDup concepts, so there's no "official" way to manage the order of indexing.
Avoid waiting for sync primitives like asyncio.Event or asyncio.Lock in handlers. Indexing will be stuck forever, waiting for the database transaction to complete.
Instead, save raw data in handlers and process it later with hooks when all conditions are met. For example, process data batch only when all indexes in the dipdup_index table have reached a specific level.
How to perform database migrations?
DipDup does not provide any tooling for database migrations. The reason is that schema changes almost always imply reindexing when speaking about indexers. However, you can perform migrations yourself using any tool you like. First, disable schema hash check in config:
advanced:
reindex:
schema_modified: ignore
You can also use the schema approve command for a single schema change.
To determine what manual modifications you need to apply after changing models.py, you can compare raw SQL schema before and after the change. Consider the following example:
- timestamp = fields.DatetimeField()
+ timestamp = fields.DatetimeField(auto_now=True)
dipdup schema export > old
# ...modify `models.py` here...
dipdup schema export > new
diff old new
76c76
< "timestamp" TIMESTAMP NOT NULL,
---
> "timestamp" TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
Now you can prepare and execute an ALTER TABLE query manually or using SQL hooks.
Troubleshooting
This page contains tips for troubleshooting DipDup issues.
Update DipDup to the latest version
DipDup framework evolves rapidly just like Tezos itself does. We recommend keeping your project up-to-date with the latest version of DipDup.
If you're using Poetry, set caret version constraint in pyproject.toml to use the latest release of the current major version:
[tool.poetry.dependencies]
python = ">=3.10,<3.11"
dipdup = "^6"
pipx installations always use latest version.
Run dipdup update periodically to update to the latest version.
While building Docker images you can use X and X.Y tags to lock to specific major/minor releases:
FROM dipdup/dipdup:6
Ensure that config is correct
DipDup config can be correct syntactically but not necessarily semantically. It's especially easy to make a mistake when actively using templates and environment variables. Use config export command to dump config the way DipDup "sees" it, after resolving all links and templates. config env command can help you to find missing environment variables.
dipdup -c dipdup.yml -c dipdup.prod.yml config export
dipdup -c dipdup.yml -c dipdup.prod.yml config env
Enable debug logging and crash reporting
More logs can give you a clue about the reason for an issue. Enable them in config:
logging: verbose
When an exception occurs DipDup saves crash dumps to /tmp/dipdup/crashdumps/XXXXXXX.json. You can send those dumps to Baking Bad automatically:
advanced:
crash_reporting: True
Use linters to find errors in your Python code
Exceptions that occurred during callback execution are reraised as CallbackErrors. If you experience this issue, most likely your code is incorrect. Luckily, the Python ecosystem has lots of tools called linters to help you find mistakes. In DipDup we mostly use a combo of flake8 and mypy. You can start using both with zero configuration:
poetry add --with dev flake8 mypy
poetry run flake8
poetry run mypy
You can find a more complex example in DipDup's pyproject.toml or use the cookiecutter template to create a new project with all recommended bells and whistles (see 1. Quickstart → from-template).
Explore contract calls in Better Call Dev
Better Call Dev is a blockchain explorer for Tezos smart contracts. It provides a more human-friendly interface than TzKT to explore exact contract calls and parameter/storage structures.
Try it out when writing index definitions.
Packaging issues
Poetry package manager we recommend using with DipDup is not the most stable software in the world. If you experience issues with it like SolverProblemError, try the following:
- Remove
.venvandpoetry.lockfrom the project root - Remove
~/.cache/pypoetryand~/.cache/pip/directories - Run
poetry installand hope for the best.
Got stuck? Ask for help
We are always ready to answer your questions!
If you think you've found a bug, please report it directly to the GitHub Issues. For all other discussions, join our socials:
Demo projects
The DipDup repository contains several minimal examples of how to use various features for real-case scenarios. Please, do not use these examples in production unmodified. We have not put a production-grade amount of effort into developing them, so they may contain flaws in indexing logic.
Some projects that started as a demo now evolved into full-fledged applications running in production. Check out 10. Built with DipDup page.
TzBTC token
source: demo_token
The most basic indexer used in Quickstart. A single operation index to track balances of TzBTC token holders, nothing else.
hic et nunc
source: demo_nft_marketplace
Indexes trades and swaps of "hic et nunc", one of the most popular NFT marketplaces on Tezos.
Quipuswap
source: demo_dex
Covers all available operations of Quipuswap DEX contracts: trades, transfers, moving liquidity. A more complex example with index templates.
Homebase RegistryDAO
source: demo_factories
Homebase enables users to create DAO contracts. In this example indexes are spawned in runtime (5.11. Index factories) for all contracts having the same script.
Tezos Domains (operation)
source: demo_domains
Tezos Domains is a distributed naming system. You probably have seen those fancy user.tez names while browsing explorers. This is a pretty basic example of how to index them.
Tezos Domains (big_map)
source: demo_big_maps
The same as above, but uses big_map index instead of operation one. The storage structure of this contract is pretty straightforward; we only need to track a single big map. This example contains skip_history: once directive to index only the current state of the contract before switching to realtime processing. It allows to speed up indexing even more.
TzColors
source: demo_auction
A very basic indexer of TzColors NFT token and marketplace. Unlike hic et nunc this marketplace provides auction functionality. Other than that, it is pretty much the same.
Built with DipDup
This page is a brief overview of projects which use DipDup as an indexing solution.
Want to see your project on this page? Create an issue on GitHub!
Rarible / Tezos marketplace indexer
Rarible is a multichain community-centric NFT marketplace, that also allows to trade on aggregated listings from other NFT platforms. Rarible uses DipDup-based solution to aggregate sells and auctions from major Tezos marketplaces.
Ubisoft / Quartz tokens metadata
Ubisoft Quartz is a new platform for players to get Digits, the first NFTs playable in AAA games. Under the hood Quartz uses Aleph as persistent token metadata storage and a non-standard token metadata signalling schema. In order to enable wallets and other TzKT API consumers with Quartz NFTs data we created a custom indexing plugin.
Youves
Youves is a decentralized, non-custodial and self-governed platform for the creation and management of synthetic assets. Youves uses DipDup-based solution to track vaults, DEX trades, and oracle price quotes.
Kord.fi
Kord.Fi is a DeFi protocol for Tezos that allows liquidity providers to tap into additional leverage provided by Tezos Blockchain asset owners.
StakeNow
StakeNow.fi gives you a 360° view of your investments and lets you manage your Tezos assets in one place.
Mavryk
Mavryk is a DAO operated financial ecosystem that lets users borrow and earn on their terms, while participating in the governance of the platform.
Vortex
Vortez is an all-in-one decentralized finance protocol on Tezos blockchain built by Smartlink. Vortex uses DipDup indexer to track AMM swaps, pools, positions, as well as yield farms, and NFT collections.
Versum
Versum combines features of NFT platforms and social platforms to introduce a marketplace that focuses on organic discovery, decentralized storage, and accessibility.
Yupana
Yupana.Finance is an open-source, decentralized, and non-custodial liquidity protocol built to securely lend and borrow digital assets via smart contracts.
HicDEX (Teia)
HicDEX is a Tezos indexer for hicetnunc.art marketplace (currently teia.art). Indexed data is available with a public GraphQL endpoint.
Homebase
Homebase is a web application that enables users to create and manage/use DAOs on the Tezos blockchain. This application aims to help empower community members and developers to launch and participate in Tezos-based DAOs.
Tezos Profiles
Tezos Profiles enables you to associate your online identity with your Tezos account.
Juster
Juster is an on-chain smart contract platform allowing users to take part in an automated betting market by creating events, providing liquidity to them, and making bets.
tz1and
A Virtual World and NFT Marketplace.
Tezotopia
Tezotopia is a Tezos-based Real-Time Strategy (RTS) gaming platform that allows players to acquire land (Tezotops), items and resources.
mempool
This is an optional section used by the mempool indexer plugin. It uses contracts and datasources aliases as well as the database connection.
Mempool configuration has two sections: settings and indexers (required).
{% page-ref page="../advanced/mempool-plugin.md" %}
Settings
This section is optional so are all the setting keys.
mempool:
settings:
keep_operations_seconds: 172800
expired_after_blocks: 60
keep_in_chain_blocks: 10
mempool_request_interval_seconds: 10
rpc_timeout_seconds: 10
indexers:
...
keep_operations_seconds
How long to store operations that did not get into the chain. After that period, such operations will be wiped from the database. Default value is 172800 seconds (2 days).
expired_after_blocks
When level(head) - level(operation.branch) >= expired_after_blocks and operation is still on in chain it's marked as expired. Default value is 60 blocks (~1 hour).
keep_in_chain_blocks
Since the main purpose of this plugin is to index mempool operations (actually it's a rolling index), all the operations that were included in the chain are removed from the database after specified period of time. Default value is 10 blocks (~10 minutes).
mempool_request_interval_seconds
How often Tezos nodes should be polled for pending mempool operations. Default value is 10 seconds.
rpc_timeout_seconds
Tezos node request timeout. Default value is 10 seconds.
Indexers
You can index several networks at once, or index different nodes independently. Indexer names are not standardized, but for clarity it's better to stick with some meaningful keys:
mempool:
settings:
...
indexers:
mainnet:
filters:
kinds:
- transaction
accounts:
- contract_alias
datasources:
tzkt: tzkt_mainnet
rpc:
- node_mainnet
edonet:
florencenet:
Each indexer object has two keys: filters and datasources (required).
Filters
An optional section specifying which mempool operations should be indexed. By default all transactions will be indexed.
kinds
Array of operations kinds, default value is transaction (single item).
The complete list of values allowed:
activate_accountballotdelegation*double_baking_evidencedouble_endorsement_evidenceendorsementorigination*proposalreveal*seed_nonce_revelationtransaction*
* — manager operations.
accounts
Array of contract aliases used to filter operations by source or destination.
NOTE: applied to manager operations only.
Datasources
Mempool plugin is tightly coupled with TzKT and Tezos node providers.
tzkt
An alias pointing to a datasource of kind tzkt is expected.
rpc
An array of aliases pointing to datasources of kind tezos-node
Polling multiple nodes allows to detect more refused operations and makes indexing more robust in general.
metadata
This is an optional section used by the metadata indexer plugin. It uses contracts and datasources aliases as well as the database connection.
Metadata configuration has two required sections: settings and indexers
Settings
metadata:
settings:
ipfs_gateways:
- https://cloudflare-ipfs.com
ipfs_timeout: 10
http_timeout: 10
max_retry_count_on_error: 3
contract_service_workers: 15
token_service_workers: 75
indexers:
...
ipfs_gateways
An array of IPFS gateways. The indexer polls them sequentially until it gets a result or runs out of attempts. It is recommended to specify more than one gateway to overcome propagation issues, rate limits, and other problems.
ipfs_timeout
How long DipDup will wait for a single IPFS gateway response. Default value is 10 seconds.
http_timeout
How long DipDup will wait for a HTTP server response. Default value is 10 seconds.
max_retry_count_on_error
If DipDup fails to get a response from IPFS gateway or HTTP server, it will try again after some time, until it runs out of attempts. Default value is 3 attempts.
contract_service_workers
Count of contract service workers which resolves contract metadata. Default value is 5.
token_service_workers
Count of token service workers which resolves token metadata. Default value is 5.
Indexers
You can index several networks at once, or go with a single one. Indexer names are not standardized, but for clarity it's better to stick with some meaningful keys:
metadata:
settings:
...
indexers:
mainnet:
filters:
accounts:
- contract_alias
datasources:
tzkt: tzkt_mainnet
Each indexer object has two keys: filters and datasources (required).
Filters
accounts
Array of contract aliases used to filter Big_map updates by the owner contract address.
Datasources
Metadata plugin is tightly coupled with TzKT provider.
tzkt
An alias pointing to a datasource of kind tzkt is expected.
dipdup¶
Manage and run DipDup indexers.
Documentation: https://docs.dipdup.io
Issues: https://github.com/dipdup-io/dipdup/issues
dipdup [OPTIONS] COMMAND [ARGS]...
Options
- --version¶
Show the version and exit.
- -c, --config <PATH>¶
A path to DipDup project config (default: dipdup.yml).
- -e, --env-file <PATH>¶
A path to .env file containing KEY=value strings.
config¶
Commands to manage DipDup configuration.
dipdup config [OPTIONS] COMMAND [ARGS]...
env¶
Dump environment variables used in DipDup config.
If variable is not set, default value will be used.
dipdup config env [OPTIONS]
Options
- -f, --file <file>¶
Output to file instead of stdout.
export¶
Print config after resolving all links and, optionally, templates.
WARNING: Avoid sharing output with 3rd-parties when –unsafe flag set - it may contain secrets!
dipdup config export [OPTIONS]
Options
- --unsafe¶
Resolve environment variables or use default values from config.
- --full¶
Resolve index templates.
hasura¶
Commands related to Hasura integration.
dipdup hasura [OPTIONS] COMMAND [ARGS]...
configure¶
Configure Hasura GraphQL Engine to use with DipDup.
dipdup hasura configure [OPTIONS]
Options
- --force¶
Proceed even if Hasura is already configured.
init¶
Generate project tree, callbacks and types.
This command is idempotent, meaning it won’t overwrite previously generated files unless asked explicitly.
dipdup init [OPTIONS]
Options
- --overwrite-types¶
Regenerate existing types.
- --keep-schemas¶
Do not remove JSONSchemas after generating types.
install¶
Install DipDup for the current user.
dipdup install [OPTIONS]
Options
- -q, --quiet¶
Use default values for all prompts.
- -f, --force¶
Force reinstall.
- -r, --ref <ref>¶
Install DipDup from a specific git ref.
- -p, --path <path>¶
Install DipDup from a local path.
migrate¶
Migrate project to the new spec version.
If you’re getting MigrationRequiredError after updating DipDup, this command will fix imports and type annotations to match the current spec_version. Review and commit changes after running it.
dipdup migrate [OPTIONS]
new¶
Create a new project interactively.
dipdup new [OPTIONS]
Options
- -q, --quiet¶
Use default values for all prompts.
- -f, --force¶
Overwrite existing files.
- -r, --replay <replay>¶
Replay a previously saved state.
run¶
Run indexer.
Execution can be gracefully interrupted with Ctrl+C or SIGINT signal.
dipdup run [OPTIONS]
schema¶
Commands to manage database schema.
dipdup schema [OPTIONS] COMMAND [ARGS]...
approve¶
Continue to use existing schema after reindexing was triggered.
dipdup schema approve [OPTIONS]
export¶
Print SQL schema including scripts from sql/on_reindex.
This command may help you debug inconsistency between project models and expected SQL schema.
dipdup schema export [OPTIONS]
init¶
Prepare a database for running DipDip.
This command creates tables based on your models, then executes sql/on_reindex to finish preparation - the same things DipDup does when run on a clean database.
dipdup schema init [OPTIONS]
wipe¶
Drop all database tables, functions and views.
WARNING: This action is irreversible! All indexed data will be lost!
dipdup schema wipe [OPTIONS]
Options
- --immune¶
Drop immune tables too.
- --force¶
Skip confirmation prompt.
status¶
Show the current status of indexes in the database.
dipdup status [OPTIONS]
uninstall¶
Uninstall DipDup for the current user.
dipdup uninstall [OPTIONS]
Options
- -q, --quiet¶
Use default values for all prompts.
update¶
Update DipDup for the current user.
dipdup update [OPTIONS]
Options
- -q, --quiet¶
Use default values for all prompts.
- -f, --force¶
Force reinstall.
Config file reference
| Header | spec_version* | 14.15. spec_version |
package* | 14.12. package | |
| Inventory | database | 14.5. database |
contracts | 14.3. contracts | |
datasources | 14.6. datasources | |
custom | 14.4. custom | |
| Index definitions | indexes | 14.9. indexes |
templates | 14.16. templates | |
| Hook definitions | hooks | 14.8. hooks |
jobs | 14.10. jobs | |
| Integrations | hasura | 14.7. hasura |
sentry | 14.14. sentry | |
prometheus | 14.13. prometheus | |
| Tunables | advanced | 14.2. advanced |
logging | 14.11. logging |
- class DipDupConfig(spec_version, package, datasources=<factory>, database=SqliteDatabaseConfig(kind='sqlite', path=':memory:'), contracts=<factory>, indexes=<factory>, templates=<factory>, jobs=<factory>, hooks=<factory>, hasura=None, sentry=SentryConfig(dsn='', environment=None, server_name=None, release=None, user_id=None, debug=False), prometheus=None, advanced=AdvancedConfig(reindex={}, scheduler=None, postpone_jobs=False, early_realtime=False, merge_subscriptions=False, metadata_interface=False, skip_version_check=False, rollback_depth=2, crash_reporting=False, decimal_precision=None, alt_operation_matcher=False), custom=<factory>, logging=LoggingValues.default)¶
Main indexer config
- Parameters:
spec_version (str) – Version of config specification, currently always 1.2
package (str) – Name of indexer’s Python package, existing or not
datasources (dict[str, TzktDatasourceConfig | CoinbaseDatasourceConfig | MetadataDatasourceConfig | IpfsDatasourceConfig | HttpDatasourceConfig]) – Mapping of datasource aliases and datasource configs
database (SqliteDatabaseConfig | PostgresDatabaseConfig) – Database config
contracts (dict[str, ContractConfig]) – Mapping of contract aliases and contract configs
indexes (dict[str, OperationIndexConfig | BigMapIndexConfig | HeadIndexConfig | TokenTransferIndexConfig | EventIndexConfig | OperationUnfilteredIndexConfig | IndexTemplateConfig]) – Mapping of index aliases and index configs
templates (dict[str, OperationIndexConfig | BigMapIndexConfig | HeadIndexConfig | TokenTransferIndexConfig | EventIndexConfig | OperationUnfilteredIndexConfig]) – Mapping of template aliases and index templates
jobs (dict[str, JobConfig]) – Mapping of job aliases and job configs
hooks (dict[str, HookConfig]) – Mapping of hook aliases and hook configs
hasura (HasuraConfig | None) – Hasura integration config
sentry (SentryConfig) – Sentry integration config
prometheus (PrometheusConfig | None) – Prometheus integration config
advanced (AdvancedConfig) – Advanced config
custom (dict[str, Any]) – User-defined configuration to use in callbacks
logging (LoggingValues) – Modify logging verbosity
- class AdvancedConfig(reindex=<factory>, scheduler=None, postpone_jobs=False, early_realtime=False, merge_subscriptions=False, metadata_interface=False, skip_version_check=False, rollback_depth=2, crash_reporting=False, decimal_precision=None, alt_operation_matcher=False)¶
Feature flags and other advanced config.
- Parameters:
reindex (dict[ReindexingReason, ReindexingAction]) – Mapping of reindexing reasons and actions DipDup performs
scheduler (dict[str, Any] | None) – apscheduler scheduler config
postpone_jobs (bool) – Do not start job scheduler until all indexes are in realtime state
early_realtime (bool) – Establish realtime connection immediately after startup
merge_subscriptions (bool) – Subscribe to all operations instead of exact channels
metadata_interface (bool) – Expose metadata interface for TzKT
skip_version_check (bool) – Do not check for new DipDup versions on startup
rollback_depth (int) – A number of levels to keep for rollback
crash_reporting (bool) – Enable crash reporting
decimal_precision (int | None) – Adjust decimal context precision.
alt_operation_matcher (bool) – Use different algorithm to match operations (undocumented)
- class BigMapHandlerConfig(callback, contract, path)¶
Big map handler config
- Parameters:
callback (str) – Callback name
contract (str | ContractConfig) – Contract to fetch big map from
path (str) – Path to big map (alphanumeric string with dots)
- class BigMapIndexConfig(kind, datasource, handlers, skip_history=SkipHistory.never, first_level=0, last_level=0)¶
Big map index config
- Parameters:
kind (Literal['big_map']) – always big_map
datasource (str | TzktDatasourceConfig) – Index datasource to fetch big maps with
handlers (tuple[BigMapHandlerConfig, ...]) – Mapping of big map diff handlers
skip_history (SkipHistory) – Fetch only current big map keys ignoring historical changes
first_level (int) – Level to start indexing from
last_level (int) – Level to stop indexing at
- class CoinbaseDatasourceConfig(kind, api_key=None, secret_key=None, passphrase=None, http=None)¶
Coinbase datasource config
- Parameters:
kind (Literal['coinbase']) – always ‘coinbase’
api_key (str | None) – API key
secret_key (str | None) – API secret key
passphrase (str | None) – API passphrase
http (HTTPConfig | None) – HTTP client configuration
- class ContractConfig(address=None, code_hash=None, typename=None)¶
Contract config
- Parameters:
address (str | None) – Contract address
code_hash (int | str | None) – Contract code hash or address to fetch it from
typename (str | None) – User-defined alias for the contract script
- class EventHandlerConfig(callback, contract, tag)¶
Event handler config
- Parameters:
callback (str) – Callback name
contract (str | ContractConfig) – Contract which emits event
tag (str) – Event tag
- class EventIndexConfig(kind, datasource, handlers=<factory>, first_level=0, last_level=0)¶
Event index config
- Parameters:
kind (Literal['event']) – Index kind
datasource (str | TzktDatasourceConfig) – Datasource config
handlers (tuple[EventHandlerConfig | UnknownEventHandlerConfig, ...]) – Event handlers
first_level (int) – First block level to index
last_level (int) – Last block level to index
- class HasuraConfig(url, admin_secret=None, create_source=False, source='default', select_limit=100, allow_aggregations=True, allow_inconsistent_metadata=False, camel_case=False, rest=True, http=None)¶
Config for the Hasura integration.
- Parameters:
url (str) – URL of the Hasura instance.
admin_secret (str | None) – Admin secret of the Hasura instance.
create_source (bool) – Whether source should be added to Hasura if missing.
source (str) – Hasura source for DipDup to configure, others will be left untouched.
select_limit (int) – Row limit for unauthenticated queries.
allow_aggregations (bool) – Whether to allow aggregations in unauthenticated queries.
allow_inconsistent_metadata (bool) – Whether to ignore errors when applying Hasura metadata.
camel_case (bool) – Whether to use camelCase instead of default pascal_case for the field names (incompatible with metadata_interface flag)
rest (bool) – Enable REST API both for autogenerated and custom queries.
http (HTTPConfig | None) – HTTP connection tunables
- class HeadHandlerConfig(callback)¶
Head block handler config
- Parameters:
callback (str) – Callback name
- class HeadIndexConfig(kind, datasource, handlers)¶
Head block index config
- Parameters:
kind (Literal['head']) – always head
datasource (str | TzktDatasourceConfig) – Index datasource to receive head blocks
handlers (tuple[HeadHandlerConfig, ...]) – Mapping of head block handlers
- class HookConfig(callback, args=<factory>, atomic=False)¶
Hook config
- Parameters:
args (dict[str, str]) – Mapping of argument names and annotations (checked lazily when possible)
atomic (bool) – Wrap hook in a single database transaction
callback (str) – Callback name
- class HTTPConfig(retry_count=None, retry_sleep=None, retry_multiplier=None, ratelimit_rate=None, ratelimit_period=None, ratelimit_sleep=None, connection_limit=None, connection_timeout=None, batch_size=None, replay_path=None)¶
Advanced configuration of HTTP client
- Parameters:
retry_count (int | None) – Number of retries after request failed before giving up
retry_sleep (float | None) – Sleep time between retries
retry_multiplier (float | None) – Multiplier for sleep time between retries
ratelimit_rate (int | None) – Number of requests per period (“drops” in leaky bucket)
ratelimit_period (int | None) – Time period for rate limiting in seconds
ratelimit_sleep (float | None) – Sleep time between requests when rate limit is reached
connection_limit (int | None) – Number of simultaneous connections
connection_timeout (int | None) – Connection timeout in seconds
batch_size (int | None) – Number of items fetched in a single paginated request (for some APIs)
replay_path (str | None) – Development-only option to use cached HTTP responses instead of making real requests
- class HttpDatasourceConfig(kind, url, http=None)¶
Generic HTTP datasource config
- Parameters:
kind (Literal['http']) – always ‘http’
url (str) – URL to fetch data from
http (HTTPConfig | None) – HTTP client configuration
- class IndexTemplateConfig(template, values, first_level=0, last_level=0)¶
Index template config
- Parameters:
kind – always template
values (dict[str, str]) – Values to be substituted in template (<key> -> value)
first_level (int) – Level to start indexing from
last_level (int) – Level to stop indexing at
template (str) – Template alias in templates section
- class IpfsDatasourceConfig(kind, url='https://ipfs.io/ipfs', http=None)¶
IPFS datasource config
- Parameters:
kind (Literal['ipfs']) – always ‘ipfs’
url (str) – IPFS node URL, e.g. https://ipfs.io/ipfs/
http (HTTPConfig | None) – HTTP client configuration
- class JobConfig(hook, args=<factory>, crontab=None, interval=None, daemon=False)¶
Job schedule config
- Parameters:
hook (str | HookConfig) – Name of hook to run
crontab (str | None) – Schedule with crontab syntax (* * * * *)
interval (int | None) – Schedule with interval in seconds
daemon (bool) – Run hook as a daemon (never stops)
args (dict[str, Any]) – Arguments to pass to the hook
- class LoggingValues(value)¶
Enum for logging field values.
- default = 'default'¶
- quiet = 'quiet'¶
- verbose = 'verbose'¶
- class MetadataDatasourceConfig(kind, network, url='https://metadata.dipdup.net', http=None)¶
DipDup Metadata datasource config
- Parameters:
kind (Literal['metadata']) – always ‘metadata’
network (MetadataNetwork) – Network name, e.g. mainnet, ghostnet, etc.
url (str) – GraphQL API URL, e.g. https://metadata.dipdup.net
http (HTTPConfig | None) – HTTP client configuration
- class OperationHandlerConfig(callback, pattern)¶
Operation handler config
- Parameters:
callback (str) – Callback name
pattern (tuple[OperationHandlerTransactionPatternConfig | OperationHandlerOriginationPatternConfig, ...]) – Filters to match operation groups
- class OperationHandlerOriginationPatternConfig(type='origination', source=None, similar_to=None, originated_contract=None, optional=False, strict=False, alias=None)¶
Origination handler pattern config
- Parameters:
type (Literal['origination']) – always ‘origination’
source (str | ContractConfig | None) – Match operations by source contract alias
similar_to (str | ContractConfig | None) – Match operations which have the same code/signature (depending on strict field)
originated_contract (str | ContractConfig | None) – Match origination of exact contract
optional (bool) – Whether can operation be missing in operation group
strict (bool) – Match operations by storage only or by the whole code
alias (str | None) – Alias for transaction (helps to avoid duplicates)
- class OperationHandlerTransactionPatternConfig(type='transaction', source=None, destination=None, entrypoint=None, optional=False, alias=None)¶
Operation handler pattern config
- Parameters:
type (Literal['transaction']) – always ‘transaction’
source (str | ContractConfig | None) – Match operations by source contract alias
destination (str | ContractConfig | None) – Match operations by destination contract alias
entrypoint (str | None) – Match operations by contract entrypoint
optional (bool) – Whether can operation be missing in operation group
alias (str | None) – Alias for transaction (helps to avoid duplicates)
- class OperationIndexConfig(kind, datasource, handlers, contracts=<factory>, types=(<OperationType.transaction: 'transaction'>, ), first_level=0, last_level=0)¶
Operation index config
- Parameters:
kind (Literal['operation']) – always operation
datasource (str | TzktDatasourceConfig) – Alias of index datasource in datasources section
handlers (tuple[OperationHandlerConfig, ...]) – List of indexer handlers
types (tuple[OperationType, ...]) – Types of transaction to fetch
contracts (list[str | ContractConfig]) – Aliases of contracts being indexed in contracts section
first_level (int) – Level to start indexing from
last_level (int) – Level to stop indexing at
- class OperationType(value)¶
Type of blockchain operation
- migration = 'migration'¶
- origination = 'origination'¶
- transaction = 'transaction'¶
- class OperationUnfilteredIndexConfig(kind, datasource, callback, types=(<OperationType.transaction: 'transaction'>, ), first_level=0, last_level=0)¶
Operation index config
- Parameters:
kind (Literal['operation_unfiltered']) – always operation_unfiltered
datasource (str | TzktDatasourceConfig) – Alias of index datasource in datasources section
callback (str) – Callback name
types (tuple[OperationType, ...]) – Types of transaction to fetch
first_level (int) – Level to start indexing from
last_level (int) – Level to stop indexing at
- class PostgresDatabaseConfig(kind, host, user='postgres', database='postgres', port=5432, schema_name='public', password='', immune_tables=<factory>, connection_timeout=60)¶
Postgres database connection config
- Parameters:
kind (Literal['postgres']) – always ‘postgres’
host (str) – Host
port (int) – Port
user (str) – User
password (str) – Password
database (str) – Database name
schema_name (str) – Schema name
immune_tables (set[str]) – List of tables to preserve during reindexing
connection_timeout (int) – Connection timeout
- class PrometheusConfig(host, port=8000, update_interval=1.0)¶
Config for Prometheus integration.
- Parameters:
host (str) – Host to bind to
port (int) – Port to bind to
update_interval (float) – Interval to update some metrics in seconds
- class ReindexingAction(value)¶
Action that should be performed on reindexing
- exception = 'exception'¶
- ignore = 'ignore'¶
- wipe = 'wipe'¶
- class ReindexingReason(value)¶
Reason that caused reindexing
- config_modified = 'config_modified'¶
- manual = 'manual'¶
- migration = 'migration'¶
- rollback = 'rollback'¶
- schema_modified = 'schema_modified'¶
- class SentryConfig(dsn='', environment=None, server_name=None, release=None, user_id=None, debug=False)¶
Config for Sentry integration.
- Parameters:
dsn (str) – DSN of the Sentry instance
environment (str | None) – Environment; if not set, guessed from docker/ci/gha/local.
server_name (str | None) – Server name; defaults to obfuscated hostname.
release (str | None) – Release version; defaults to DipDup package version.
user_id (str | None) – User ID; defaults to obfuscated package/environment.
debug (bool) – Catch warning messages, increase verbosity.
- class SkipHistory(value)¶
Whether to skip indexing operation history and use only current state
- always = 'always'¶
- never = 'never'¶
- once = 'once'¶
- class SqliteDatabaseConfig(kind, path=':memory:')¶
SQLite connection config
- Parameters:
kind (Literal['sqlite']) – always ‘sqlite’
path (str) – Path to .sqlite3 file, leave default for in-memory database (:memory:)
- class TokenTransferHandlerConfig(callback, contract=None, token_id=None, from_=None, to=None)¶
Token transfer handler config
- Parameters:
callback (str) – Callback name
contract (str | ContractConfig | None) – Filter by contract
token_id (int | None) – Filter by token ID
from – Filter by sender
to (str | ContractConfig | None) – Filter by recipient
from_ (str | ContractConfig | None) –
- class TokenTransferIndexConfig(kind, datasource, handlers=<factory>, first_level=0, last_level=0)¶
Token transfer index config
- Parameters:
kind (Literal['token_transfer']) – always token_transfer
datasource (str | TzktDatasourceConfig) – Index datasource to use
handlers (tuple[TokenTransferHandlerConfig, ...]) – Mapping of token transfer handlers
first_level (int) – Level to start indexing from
last_level (int) – Level to stop indexing at
- class TzktDatasourceConfig(kind, url='https://api.tzkt.io', http=None, buffer_size=0)¶
TzKT datasource config
- Parameters:
kind (Literal['tzkt']) – always ‘tzkt’
url (str) – Base API URL, e.g. https://api.tzkt.io/
http (HTTPConfig | None) – HTTP client configuration
buffer_size (int) – Number of levels to keep in FIFO buffer before processing
- class UnknownEventHandlerConfig(callback, contract)¶
Unknown event handler config
- Parameters:
callback (str) – Callback name
contract (str | ContractConfig) – Contract which emits event
advanced
advanced:
early_realtime: False
merge_subscriptions: False
postpone_jobs: False
reindex:
manual: wipe
migration: exception
rollback: ignore
config_modified: exception
schema_modified: exception
This config section allows users to tune some system-wide options, either experimental or unsuitable for generic configurations.
| field | description |
|---|---|
reindex | Mapping of reindexing reasons and actions DipDup performs |
scheduler | apscheduler scheduler config |
postpone_jobs | Do not start job scheduler until all indexes are in realtime state |
early_realtime | Establish realtime connection immediately after startup |
merge_subscriptions | Subscribe to all operations instead of exact channels |
metadata_interface | Expose metadata interface for TzKT |
CLI flags have priority over self-titled AdvancedConfig fields.
contracts
A list of the contracts you can use in the index definitions. Each contract entry has two fields:
address— either originated or implicit account address encoded in base58.typename— an alias for the particular contract script, meaning that two contracts sharing the same code can have the same type name.
contracts:
kusd_dex_mainnet:
address: KT1CiSKXR68qYSxnbzjwvfeMCRburaSDonT2
typename: quipu_fa12
tzbtc_dex_mainnet:
address: KT1N1wwNPqT5jGhM91GQ2ae5uY8UzFaXHMJS
typename: quipu_fa12
kusd_token_mainnet:
address: KT1K9gCRgaLRFKTErYt1wVxA3Frb9FjasjTV
typename: kusd_token
tzbtc_token_mainnet:
address: KT1PWx2mnDueood7fEmfbBDKx1D9BAnnXitn
typename: tzbtc_token
If the typename field is not set, a contract alias will be used instead.
Contract entry does not contain information about the network, so it's a good idea to include the network name in the alias. This design choice makes possible a generic index parameterization via templates. See 2.7. Templates and variables for details.
If multiple contracts you index have the same interface but different code, see 7. F.A.Q. to learn how to avoid conflicts.
custom
An arbitrary YAML object you can use to store internal indexer configuration.
package: my_indexer
...
custom:
foo: bar
Access or modify it from any callback:
ctx.config.custom['foo'] = 'buzz'
database
DipDup supports several database engines for development and production. The obligatory field kind specifies which engine has to be used:
sqlitepostgres(and compatible engines)
6.1. Database engines article may help you choose a database that better suits your needs.
SQLite
path field must be either path to the .sqlite3 file or :memory: to keep a database in memory only (default):
database:
kind: sqlite
path: db.sqlite3
| field | description |
|---|---|
kind | always 'sqlite' |
path | Path to .sqlite3 file, leave default for in-memory database |
PostgreSQL
Requires host, port, user, password, and database fields. You can set schema_name to values other than public, but Hasura integration won't be available.
database:
kind: postgres
host: db
port: 5432
user: dipdup
password: ${POSTGRES_PASSWORD:-changeme}
database: dipdup
schema_name: public
| field | description |
|---|---|
kind | always 'postgres' |
host | Host |
port | Port |
user | User |
password | Password |
database | Database name |
schema_name | Schema name |
immune_tables | List of tables to preserve during reindexing |
connection_timeout | Connection timeout in seconds |
You can also use compose-style environment variable substitutions with default values for secrets and other fields. See 2.7. Templates and variables.
Immune tables
You might want to keep several tables during schema wipe if the data in them is not dependent on index states yet heavy. A typical example is indexing IPFS data — changes in your code won't affect off-chain storage, so you can safely reuse this data.
database:
immune_tables:
- ipfs_assets
immune_tables is an optional array of table names that will be ignored during schema wipe. Once an immune table is created, DipDup will never touch it again; to change the schema of an immune table, you need to perform a migration manually. Check schema export output before doing this to ensure the resulting schema is the same as Tortoise ORM would generate.
datasources
A list of API endpoints DipDup uses to retrieve indexing data to process.
A datasource config entry is an alias for the endpoint URI; there's no network mention. Thus it's good to add a network name to the datasource alias, e.g. tzkt_mainnet.
tzkt
datasources:
tzkt:
kind: tzkt
url: ${TZKT_URL:-https://api.tzkt.io}
http:
retry_count: # retry infinetely
retry_sleep:
retry_multiplier:
ratelimit_rate:
ratelimit_period:
connection_limit: 100
connection_timeout: 60
batch_size: 10000
buffer_size: 0
coinbase
datasources:
coinbase:
kind: coinbase
dipdup-metadata
datasources:
metadata:
kind: metadata
url: https://metadata.dipdup.net
network: mainnet|ghostnet|mumbainet
ipfs
datasources:
ipfs:
kind: ipfs
url: https://ipfs.io/ipfs
hasura
This optional section used by DipDup executor to automatically configure Hasura engine to track your tables.
hasura:
url: http://hasura:8080
admin_secret: ${HASURA_ADMIN_SECRET:-changeme}
allow_aggregations: false
camel_case: true
rest: true
select_limit: 100
source: default
hooks
Hooks are user-defined callbacks you can execute with a job scheduler or within another callback (with ctx.fire_hook).
hooks:
calculate_stats:
callback: calculate_stats
atomic: False
args:
major: bool
depth: int
jobs
Add the following section to DipDup config:
jobs:
midnight_stats:
hook: calculate_stats
crontab: "0 0 * * *"
args:
major: True
leet_stats:
hook: calculate_stats
interval: 1337 # in seconds
args:
major: False
If you're unfamiliar with the crontab syntax, an online service crontab.guru will help you build the desired expression.
logging
You can configure an amount of logging output by modifying the logging field.
logging: default | quiet | verbose
At the moment these values are equal to setting dipdup log level to INFO, WARNING or DEBUG, but this may change in the future.
package
DipDup uses this field to discover the Python package of your project.
package: my_indexer_name
DipDup will search for a module named my_module_name in PYTHONPATH
This field helps to decouple DipDup configuration file from the indexer implementation and gives more flexibility in managing the source code.
See 2.4. Project structure for details.
prometheus
prometheus:
host: 0.0.0.0
Prometheus integration options
| field | description |
|---|---|
host | Host to bind to |
port | Port to bind to |
update_interval | Interval to update some metrics in seconds |
sentry
sentry:
dsn: https://...
environment: dev
debug: False
| field | description |
|---|---|
dsn | DSN of the Sentry instance |
environment | Environment to report to Sentry (informational only) |
debug | Catch warning messages and more context |
spec_version
The DipDup specification version defines the format of the configuration file and available features.
spec_version: 1.2
This table shows which specific SDK releases support which DipDup file versions.
spec_version value | Supported DipDup versions |
|---|---|
| 0.1 | >=0.0.1, <= 0.4.3 |
| 1.0 | >=1.0.0, <=1.1.2 |
| 1.1 | >=2.0.0, <=2.0.9 |
| 1.2 | >=3.0.0 |
If you're getting MigrationRequiredError after updating the framework, run the dipdup migrate command to perform project migration.
At the moment, spec_version has not changed for a very long time. Consider recreating the package from scratch and migrating logic manually if you have another value in your configuration file.
templates
indexes:
foo:
kind: template
name: bar
first_level: 12341234
template_values:
network: mainnet
templates:
bar:
kind: index
datasource: tzkt_<network> # resolves into `tzkt_mainnet`
...
| field | description |
|---|---|
kind | always template |
name | Name of index template |
template_values | Values to be substituted in template (<key> → value) |
first_level | Level to start indexing from |
last_level | Level to stop indexing at (DipDup will terminate at this level) |
Changelog
All notable changes to this project will be documented in this file.
The format is based on Keep a Changelog, and this project adheres to Semantic Versioning.
Unreleased
Fixed
- cli: Fixed
initcrash when package name is equal to one of the project typenames.
6.5.7 - 2022-05-30
Added
- config: Added
advanced.decimal_precisionoption to adjust decimal context precision.
Fixed
- database: Fixed
OperationalErrorraised in some cases after callingbulk_create. - database: Allow running project scripts and queries on SQLite.
- database: Don't cleanup model updates on every loop.
- http: Mark
asyncio.TimeoutErrorexception as safe to retry.
Other
- http: Deserialize JSON responses with
orjson.
6.5.6 - 2022-05-02
Fixed
- config: Fixed crash due to incorrect parsing of
eventindex definitions. - http: Fixed waiting for response indefinitely when IPFS hash is not available.
Other
- ci: Slim Docker image updated to Alpine 3.17.
- metadata: Added
nairobinetto supported networks.
6.5.5 - 2022-04-17
Fixed
- config: Enable early realtime mode when config contains bigmap indexes with
skip_history. - http: Fixed crash when using custom datasources.
- index: Allow mixing
sourceandentrypointfilters inoperationindex pattern.
Other
- ci: Default git branch switched to
next.
6.5.4 - 2022-03-31
Fixed
- config: Fixed incorrest parsing of
token_transferindex filters.
Other
- deps: Updated pytezos to 3.9.0.
6.5.3 - 2022-03-28
Fixed
- cli: Don't enforce logging
DeprecationWarningwarnings. - cli: Fixed
BrokenPipeErrormessages when interrupting with DipDup with SIGINT. - config: Fixed crash when
token_transferindex hasfromortofilter.
Security
- hasura: Forbid using Hasura instances affected by GHSA-c9rw-rw2f-mj4x.
6.5.2 - 2023-03-09
Fixed
- codegen: Fixed type generation for contracts with "default" entrypoint.
- metadata: Add "mumbainet" to available networks.
- sentry: Fixed bug leading to crash reports not being sent in some cases.
- sentry: Fixed crash report grouping.
Deprecated
- ci:
-slimimages will be based on Ubuntu instead of Alpine in the next major release.
6.5.1 - 2023-02-21
Fixed
- codegen: Fixed bug leading to incorrect imports in generated callbacks in some cases.
- codegen: Fixed validation of created package after
dipdup init. - config: Allow using empty string as default env (
{DEFAULT_EMPTY:-}).
Other
- deps: Updated pydantic to 1.10.5
- deps: Updated datamodel-code-generator to 0.17.1
- deps: Updated tortoise-orm to 0.19.3
- deps: Updated pytezos to 3.8.0
6.5.0 - 2023-01-28
Added
- hasura: Apply arbitrary metadata from
hasuraproject directory. - config: Added
allow_inconsistent_metadataoption tohasurasection.
Fixed
- config: Do not include coinbase datasource credentials in config repr.
- database: Fixed crash when schema generation should fail with
schema_modified. - hasura: Stop using deprecated schema/metadata API.
- index: Fixed unnecessary prefetching of migration originations in
operationindex. - index: Remove disabled indexes from the dispatcher queue.
- sentry: Flush and reopen session daily.
- tzkt: Fixed
OperationData.typefield value for migration originations. - tzkt: Added missing
last_levelargument to migration origination fetching methods.
Other
- tzkt: Updated current testnet protocol (
limanet). - deps: Updated asyncpg to 0.27.0
- deps: Updated hasura to 2.17.0
6.4.3 - 2023-01-05
Fixed
- context: Fixed order of
add_contractmethod arguments. - index: Fixed matching operations when both
addressandcode_hashfilters are specified. - sentry: Fixed sending crash reports when DSN is not set implicitly.
- sentry: Increase event length limit.
6.4.2 - 2022-12-31
Added
- config: Added
http.ratelimit_sleepoption to set fixed sleep time on 429 responses. - context: Allow adding contracts by code hash in runtime.
Fixed
- http: Fixed merging user-defined HTTP settings and datasource defaults.
- tzkt: Fixed iterating over big map keys.
6.4.1 - 2022-12-22
Fixed
- models: Fixed package model detection.
6.4.0 - 2022-12-20
Fixed
- cli:
updateanduninstallcommands no longer require a valid config. - cli: Fixed a regression in
newcommand leading to crash withTypeError. - config: Fixed
jobssection deserialization. - database: Ignore abstract models during module validation.
6.4.0rc1 - 2022-12-09
Added
- config: Added optional
code_hashfield to contract config. - context: Added
first_levelandlast_levelarguments toctx.add_indexmethods. - index: Filtering by
code_hashis available foroperationindex. - tzkt: Added datasource methods
get_contract_addressandget_contract_hashes. - tzkt: Originations and operations now can be fetched by contract code hashes.
- tzkt: Added
sender_code_hashandtarget_code_hashfields toOperationDatamodel.
Fixed
- codegen: Unresolved index templates are now correctly processed during types generation.
- demos: Fixed outdated
demo_daoproject. - http: Fixed a crash when datasource URL contains trailing slash.
- metadata: Add
limanetto supported networks. - projects: Do not scaffold an outdated
poetry.lock.
Changed
- demos: Demos were renamed to better indicate their purpose.
- exceptions:
FrameworkExceptionis raised instead of plainRuntimeErrorwhen a framework error occurs. - exceptions: Known exceptions are inherited from
FrameworkError. - tzkt: Some datasource methods have changed their signatures.
Deprecated
- config:
similar_to.addressfilter is an alias fororiginated_contract.code_hashand will be removed in the next major release. - config:
DipDupErroris an alias forFrameworkErrorand will be removed in the next major release.
6.3.1 - 2022-11-25
Fixed
- cli: Do not apply cli hacks on module import.
- codegen: Include PEP 561 marker in generated packages.
- codegen: Untyped originations are now correctly handled.
- codegen: Fixed
aliasconfig field having no effect on originations. - codegen: Fixed optional arguments in generated callbacks.
- config: Suggest snake_case for package name.
- config: Fixed crash with
RuntimeErrorwhen index has no subscriptions. - http: Limit aiohttp sessions to specific base URL.
- index: Do not deserialize originations matched by the
sourcefilter. - index: Wrap storage deserialization exceptions with
InvalidDataError. - projects: Fixed Hasura environment in docker-compose examples.
Security
- hasura: Forbid using Hasura instances running vulnerable versions (GHSA-g7mj-g7f4-hgrg)
Other
- ci:
mypy --strictis now enforced on a codebase. - ci: Finished migration to
pytest.
6.3.0 - 2022-11-15
Added
- context: Added
execute_sql_querymethod to run queries fromsqlproject directory. - context:
execute_sqlmethod now accepts arbitrary arguments to format SQL script (unsafe, use with caution). - index: New filters for
token_transferindex.
Fixed
- cli: Fixed missing log messages from
ctx.logger. - codegen: Better PEP 8 compatibility of generated callbacks.
- context: Fixed SQL scripts executed in the wrong order.
- context: Fixed
execute_sqlmethod crashes when the path is not a directory. - database: Fixed crash with
CannotConnectNowErrorbefore establishing the database connection. - database: Fixed crash when using F expressions inside versioned transactions.
- http: Fixed caching datasource responses when
replay_pathcontains tilde. - http: Adjusted per-datasource default config values.
- project: Use the latest stable version instead of hardcoded values.
- tzkt: Fixed deserializing of
EventDataandOperationDatamodels. - tzkt: Fixed matching migration originations by address.
Deprecated
- ci:
pytezosextra and corresponding Docker image are deprecated.
6.2.0 - 2022-10-12
Added
- cli:
newcommand to create a new project interactively. - cli:
install/update/uninstallcommands to manage local DipDup installation. - index: New index kind
eventto process contract events. - install: New interactive installer based on pipx (
install.pyordipdup-install).
Fixed
- cli: Fixed commands that don't require a valid config yet crash with
ConfigurationError. - codegen: Fail on demand when
datamodel-codegenis not available. - codegen: Fixed Jinja2 template caching.
- config: Allow
sentry.dsnfield to be empty. - config: Fixed greedy environment variable regex.
- hooks: Raise a
FeatureAvailabilityHookinstead of a warning when trying to execute hooks on SQLite.
Improved
- cli: Detect
src/layout when guessing package path. - codegen: Improved cross-platform compatibility.
- config:
sentry.user_idoption to set user ID for Sentry (affects release adoption data). - sentry: Detect environment when not set in config (docker/gha/tests/local)
- sentry: Expose more tags under the
dipdupnamespace.
Performance
- cli: Up to 5x faster startup for some commands.
Security
- sentry: Prevent Sentry from leaking hostname if
server_nameis not set. - sentry: Notify about using Sentry when DSN is set or crash reporting is enabled.
Other
- ci: A significantly faster execution of GitHub Actions.
- docs: Updated "Contributing Guide" page.
6.1.3 - 2022-09-21
Added
- sentry: Enable crash-free session reporting.
Fixed
- metadata: Updated protocol aliases.
- sentry: Unwrap
CallbackErrortraceback to fix event grouping. - sentry: Hide "attempting to send..." message on shutdown.
Other
- ci: Do not build default and
-pytezosnightly images.
6.1.2 - 2022-09-16
Added
- config: Added
aliasfield to operation pattern items. - tzkt: Added quote field
gbp.
Fixed
- config: Require aliases for multiple operations with the same entrypoint.
- http: Raise
InvalidRequestErroron 204 No Content responses. - tzkt: Verify API version on datasource initialization.
- tzkt: Remove deprecated block field
priority.
6.1.1 - 2022-09-01
Fixed
- ci: Lock Pydantic to 1.9.2 to avoid breaking changes in dataclasses.
6.1.0 - 2022-08-30
Added
- ci: Build
arm64images for M1/M2 silicon. - ci: Build
-slimimages based on Alpine Linux. - ci: Introduced official MacOS support.
- ci: Introduced interactive installer (dipdup.io/install.py).
6.0.1 - 2022-08-19
Fixed
- codegen: Fixed invalid
models.pytemplate. - context: Do not wrap known exceptions with
CallbackError. - database: Raise
DatabaseConfigurationErrorwhen backward relation name equals table name. - database: Wrap schema wiping in a transaction to avoid orphaned tables in the immune schema.
- hasura: Fixed processing M2M relations.
- sentry: Fixed "invalid value
environment" error. - sentry: Ignore events from project callbacks when
crash_reportingis enabled.
6.0.0 - 2022-08-08
This release contains no changes except for the version number.
6.0.0rc2 - 2022-08-06
Added
- config: Added
advanced.crash_reportingflag to enable reporting crashes to Baking Bad. - dipdup: Save Sentry crashdump in
/tmp/dipdup/crashdumps/XXXXXXX.jsonon a crash.
Fixed
- config: Do not perform env variable substitution in commented-out lines.
Removed
- cli:
--logging-configoption is removed. - cli: All
runcommand flags are removed. Use theadvancedsection of the config. - cli:
cache showandcache clearcommands are removed. - config:
http.cacheflag is removed.
6.0.0-rc1 - 2022-07-26
Added
- cli: Added
config export --fullflag to resolve templates before printing config. - config: Added
advanced.rollback_depthfield, a number of levels to keep in a database for rollback. - context: Added
rollbackmethod to perform database rollback. - database: Added an internal
ModelUpdatemodel to store the latest database changes.
Fixed
- prometheus: Fixed updating
dipdup_index_handlers_matched_totalmetric.
Changed
- codegen:
on_index_rollbackhook callsctx.rollbackby default. - database: Project models must be subclassed from
dipdup.models.Model - database:
bulk_createandbulk_updatemodel methods are no longer supported.
Removed
- hooks: Removed deprecated
on_rollbackhook. - index: Do not try to avoid single-level rollbacks by comparing operation hashes.
5.2.5 - 2022-07-26
Fixed
- index: Fixed crash when adding an index with new subscriptions in runtime.
5.2.4 - 2022-07-17
Fixed
- cli: Fixed logs being printed to stderr instead of stdout.
- config: Fixed job scheduler not starting when config contains no indexes.
5.2.3 - 2022-07-07
Added
- sentry: Allow customizing
server_nameandreleasetags with corresponding fields in Sentry config.
Fixed
- cli: Fixed
hasura configurecommand crash when models have emptyMeta.table. - config: Removed secrets from config
__repr__.
5.2.2 - 2022-07-03
Fixed
- hasura: Fixed metadata generation.
5.2.1 - 2022-07-02
Fixed
- cli: Fixed setting default logging level.
- hasura: Fixed metadata generation for relations with a custom field name.
- hasura: Fixed configuring existing instances after changing
camel_casefield in config.
5.2.0 - 2022-06-28
Added
- config: Added
loggingconfig field. - config: Added
hasura.create_sourceflag to create PostgreSQL source if missing.
Fixed
- hasura: Do not apply table customizations to tables from other sources.
Deprecated
- cli:
--logging-configoption is deprecated. - cli: All
runcommand flags are deprecated. Use theadvancedsection of the config. - cli:
cache showandcache clearcommands are deprecated. - config:
http.cacheflag is deprecated.
5.1.7 - 2022-06-15
Fixed
- index: Fixed
token_transferindex not receiving realtime updates.
5.1.6 - 2022-06-08
Fixed
- cli: Commands with
--helpoption no longer require a working DipDup config. - index: Fixed crash with
RuntimeErrorafter continuous realtime connection loss.
Performance
- cli: Lazy import dependencies to speed up startup.
Other
- docs: Migrate docs from GitBook to mdbook.
5.1.5 - 2022-06-05
Fixed
- config: Fixed crash when rollback hook is about to be called.
5.1.4 - 2022-06-02
Fixed
- config: Fixed
OperationIndexConfig.typesfield being partially ignored. - index: Allow mixing oneshot and regular indexes in a single config.
- index: Call rollback hook instead of triggering reindex when single-level rollback has failed.
- index: Fixed crash with
RuntimeErrorafter continuous realtime connection loss. - tzkt: Fixed
originationsubscription missing whenmerge_subscriptionsflag is set.
Performance
- ci: Decrease the size of generic and
-pytezosDocker images by 11% and 16%, respectively.
5.1.3 - 2022-05-26
Fixed
- database: Fixed special characters in password not being URL encoded.
Performance
- context: Do not reinitialize config when adding a single index.
5.1.2 - 2022-05-24
Added
- tzkt: Added
originated_contract_tzipsfield toOperationData.
Fixed
- jobs: Fixed jobs with
daemonschedule never start. - jobs: Fixed failed jobs not throwing exceptions into the main loop.
Other
- database: Tortoise ORM updated to
0.19.1.
5.1.1 - 2022-05-13
Fixed
- index: Ignore indexes with different message types on rollback.
- metadata: Add
ithacanetto available networks.
5.1.0 - 2022-05-12
Added
- ci: Push
XandX.Ytags to the Docker Hub on release. - cli: Added
config envcommand to export env-file with default values. - cli: Show warning when running an outdated version of DipDup.
- hooks: Added a new hook
on_index_rollbackto perform per-index rollbacks.
Fixed
- index: Fixed fetching
migrationoperations. - tzkt: Fixed possible data corruption when using the
buffer_sizeoption. - tzkt: Fixed reconnection due to
websocketsmessage size limit.
Deprecated
- hooks: The
on_rollbackdefault hook is superseded byon_index_rollbackand will be removed later.
5.0.4 - 2022-05-05
Fixed
- exceptions: Fixed incorrect formatting and broken links in help messages.
- index: Fixed crash when the only index in config is
head. - index: Fixed fetching originations during the initial sync.
5.0.3 - 2022-05-04
Fixed
- index: Fixed crash when no block with the same level arrived after a single-level rollback.
- index: Fixed setting initial index level when
IndexConfig.first_levelis set. - tzkt: Fixed delayed emitting of buffered realtime messages.
- tzkt: Fixed inconsistent behavior of
first_level/last_levelarguments in different getter methods.
5.0.2 - 2022-04-21
Fixed
- context: Fixed reporting incorrect reindexing reason.
- exceptions: Fixed crash with
FrozenInstanceErrorwhen an exception is raised from a callback. - jobs: Fixed graceful shutdown of daemon jobs.
Improved
- codegen: Refined
on_rollbackhook template. - exceptions: Updated help messages for known exceptions.
- tzkt: Do not request reindexing if missing subgroups have matched no handlers.
5.0.1 - 2022-04-12
Fixed
- cli: Fixed
schema initcommand crash with SQLite databases. - index: Fixed spawning datasources in oneshot mode.
- tzkt: Fixed processing realtime messages.
5.0.0 - 2022-04-08
This release contains no changes except for the version number.
5.0.0-rc4 - 2022-04-04
Added
- tzkt: Added ability to process realtime messages with lag.
4.2.7 - 2022-04-02
Fixed
- config: Fixed
jobsconfig section validation. - hasura: Fixed metadata generation for v2.3.0 and above.
- tzkt: Fixed
get_originated_contractsandget_similar_contractsmethods response.
5.0.0-rc3 - 2022-03-28
Added
- config: Added
customsection to store arbitrary user data.
Fixed
- config: Fixed default SQLite path (
:memory:). - tzkt: Fixed pagination in several getter methods.
- tzkt: Fixed data loss when
skip_historyoption is enabled.
Removed
- config: Removed dummy
advanced.oneshotflag. - cli: Removed
docker initcommand. - cli: Removed dummy
schema approve --hashesflag.
5.0.0-rc2 - 2022-03-13
Fixed
- tzkt: Fixed crash in methods that do not support cursor pagination.
- prometheus: Fixed invalid metric labels.
5.0.0-rc1 - 2022-03-02
Added
- metadata: Added
metadata_interfacefeature flag to expose metadata in TzKT format. - prometheus: Added ability to expose Prometheus metrics.
- tzkt: Added missing fields to the
HeadBlockDatamodel. - tzkt: Added
iter_...methods to iterate over item batches.
Fixed
- tzkt: Fixed possible OOM while calling methods that support pagination.
- tzkt: Fixed possible data loss in
get_originationsandget_quotesmethods.
Changed
- tzkt: Added
offsetandlimitarguments to all methods that support pagination.
Removed
- bcd: Removed
bcddatasource and config section.
Performance
- dipdup: Use fast
orjsonlibrary instead of built-injsonwhere possible.
4.2.6 - 2022-02-25
Fixed
- database: Fixed generating table names from uppercase model names.
- http: Fixed bug that leads to caching invalid responses on the disk.
- tzkt: Fixed processing realtime messages with data from multiple levels.
4.2.5 - 2022-02-21
Fixed
- database: Do not add the
schemaargument to the PostgreSQL connection string when not needed. - hasura: Wait for Hasura to be configured before starting indexing.
4.2.4 - 2022-02-14
Added
- config: Added
httpdatasource to making arbitrary http requests.
Fixed
- context: Fixed crash when calling
fire_hookmethod. - context: Fixed
HookConfig.atomicflag, which was ignored infire_hookmethod. - database: Create missing tables even if
Schemamodel is present. - database: Fixed excess increasing of
decimalcontext precision. - index: Fixed loading handler callbacks from nested packages (@veqtor).
Other
- ci: Added GitHub Action to build and publish Docker images for each PR opened.
4.2.3 - 2022-02-08
Fixed
- ci: Removed
black 21.12b0dependency since bug indatamodel-codegen-generatoris fixed. - cli: Fixed
config exportcommand crash whenadvanced.reindexdictionary is present. - cli: Removed optionals from
config exportoutput so the result can be loaded again. - config: Verify
advanced.schedulerconfig for the correctness and unsupported features. - context: Fixed ignored
waitargument offire_hookmethod. - hasura: Fixed processing relation fields with missing
related_name. - jobs: Fixed default
apschedulerconfig. - tzkt: Fixed crash occurring when reorg message is the first one received by the datasource.
4.2.2 - 2022-02-01
Fixed
- config: Fixed
ipfsdatasource config.
4.2.1 - 2022-01-31
Fixed
- ci: Added
black 21.12b0dependency to avoid possible conflict withdatamodel-codegen-generator.
4.2.0 - 2022-01-31
Added
- context: Added
waitargument tofire_hookmethod to escape current transaction context. - context: Added
ctx.get_<kind>_datasourcehelpers to avoid type casting. - hooks: Added ability to configure
apschedulerwithAdvancedConfig.schedulerfield. - http: Added
requestmethod to send arbitrary requests (affects all datasources). - ipfs: Added
ipfsdatasource to download JSON and binary data from IPFS.
Fixed
- http: Removed dangerous method
close_session. - context: Fixed help message of
IndexAlreadyExistsErrorexception.
Deprecated
- bcd: Added deprecation notice.
Other
- dipdup: Removed unused internal methods.
4.1.2 - 2022-01-27
Added
- cli: Added
schema wipe --forceargument to skip confirmation prompt.
Fixed
- cli: Show warning about deprecated
--hashesargument - cli: Ignore
SIGINTsignal when shutdown is in progress. - sentry: Ignore exceptions when shutdown is in progress.
4.1.1 - 2022-01-25
Fixed
- cli: Fixed stacktraces missing on exception.
- cli: Fixed wrapping
OSErrorwithConfigurationErrorduring config loading. - hasura: Fixed printing help messages on
HasuraError. - hasura: Preserve a list of sources in Hasura Cloud environments.
- hasura: Fixed
HasuraConfig.sourceconfig option.
Changed
- cli: Unknown exceptions are no longer wrapped with
DipDupError.
Performance
- hasura: Removed some useless requests.
4.1.0 - 2022-01-24
Added
- cli: Added
schema initcommand to initialize database schema. - cli: Added
--forceflag tohasura configurecommand. - codegen: Added support for subpackages inside callback directories.
- hasura: Added
dipdup_head_statusview and REST endpoint. - index: Added an ability to skip historical data while synchronizing
big_mapindexes. - metadata: Added
metadatadatasource. - tzkt: Added
get_big_mapandget_contract_big_mapsdatasource methods.
4.0.5 - 2022-01-20
Fixed
- index: Fixed deserializing manually modified typeclasses.
4.0.4 - 2022-01-17
Added
- cli: Added
--keep-schemasflag toinitcommand to preserve JSONSchemas along with generated types.
Fixed
- demos: Tezos Domains and Homebase DAO demos were updated from edo2net to mainnet contracts.
- hasura: Fixed missing relations for models with
ManyToManyFieldfields. - tzkt: Fixed parsing storage with nested structures.
Performance
- dipdup: Minor overall performance improvements.
Other
- ci: Cache virtual environment in GitHub Actions.
- ci: Detect CI environment and skip tests that fail in GitHub Actions.
- ci: Execute tests in parallel with
pytest-xdistwhen possible. - ci: More strict linting rules of
flake8.
4.0.3 - 2022-01-09
Fixed
- tzkt: Fixed parsing parameter with an optional value.
4.0.2 - 2022-01-06
Added
- tzkt: Added optional
delegate_addressanddelegate_aliasfields toOperationData.
Fixed
- tzkt: Fixed crash due to unprocessed pysignalr exception.
- tzkt: Fixed parsing
OperationData.amountfield. - tzkt: Fixed parsing storage with top-level boolean fields.
4.0.1 - 2021-12-30
Fixed
- codegen: Fixed generating storage typeclasses with
Unionfields. - codegen: Fixed preprocessing contract JSONSchema.
- index: Fixed processing reindexing reason saved in the database.
- tzkt: Fixed processing operations with default entrypoint and empty parameter.
- tzkt: Fixed crash while recursively applying bigmap diffs to the storage.
Performance
- tzkt: Increased speed of applying bigmap diffs to operation storage.
4.0.0 - 2021-12-24
This release contains no changes except for the version number.
4.0.0-rc3 - 2021-12-20
Fixed
- cli: Fixed missing
schema approve --hashesargument. - codegen: Fixed contract address used instead of an alias when typename is not set.
- tzkt: Fixed processing operations with entrypoint
default. - tzkt: Fixed regression in processing migration originations.
- tzkt: Fixed filtering of big map diffs by the path.
Removed
- cli: Removed deprecated
run --oneshotargument andclear-cachecommand.
4.0.0-rc2 - 2021-12-11
Migration
- Run
dipdup initcommand to generateon_synchronizedhook stubs.
Added
- hooks: Added
on_synchronizedhook, which fires each time all indexes reach realtime state.
Fixed
- cli: Fixed config not being verified when invoking some commands.
- codegen: Fixed generating callback arguments for untyped operations.
- index: Fixed incorrect log messages, remove duplicate ones.
- index: Fixed crash while processing storage of some contracts.
- index: Fixed matching of untyped operations filtered by
sourcefield (@pravin-d).
Performance
- index: Checks performed on each iteration of the main DipDup loop are slightly faster now.
4.0.0-rc1 - 2021-12-02
Migration
- Run
dipdup schema approvecommand on every database you want to use with 4.0.0-rc1. Runningdipdup migrateis not necessary sincespec_versionhasn't changed in this release.
Added
- cli: Added
run --early-realtimeflag to establish a realtime connection before all indexes are synchronized. - cli: Added
run --merge-subscriptionsflag to subscribe to all operations/big map diffs during realtime indexing. - cli: Added
statuscommand to print the current status of indexes from the database. - cli: Added
config export [--unsafe]command to print config after resolving all links and variables. - cli: Added
cache showcommand to get information about file caches used by DipDup. - config: Added
first_levelandlast_leveloptional fields toTemplateIndexConfig. These limits are applied after ones from the template itself. - config: Added
daemonboolean field toJobConfigto run a single callback indefinitely. Conflicts withcrontabandintervalfields. - config: Added
advancedtop-level section.
Fixed
- cli: Fixed crashes and output inconsistency when piping DipDup commands.
- cli: Fixed
schema wipe --immuneflag being ignored. - codegen: Fixed missing imports in handlers generated during init.
- coinbase: Fixed possible data inconsistency caused by caching enabled for method
get_candles. - http: Fixed increasing sleep time between failed request attempts.
- index: Fixed invocation of head index callback.
- index: Fixed
CallbackErrorraised instead ofReindexingRequiredErrorin some cases. - tzkt: Fixed resubscribing when realtime connectivity is lost for a long time.
- tzkt: Fixed sending useless subscription requests when adding indexes in runtime.
- tzkt: Fixed
get_originated_contractsandget_similar_contractsmethods whose output was limited toHTTPConfig.batch_sizefield. - tzkt: Fixed lots of SignalR bugs by replacing
aiosignalrcorelibrary withpysignalr.
Changed
- cli:
dipdup schema wipecommand now requires confirmation when invoked in the interactive shell. - cli:
dipdup schema approvecommand now also causes a recalculation of schema and index config hashes. - index: DipDup will recalculate respective hashes if reindexing is triggered with
config_modified: ignoreorschema_modified: ignorein advanced config.
Deprecated
- cli:
run --oneshotoption is deprecated and will be removed in the next major release. The oneshot mode applies automatically whenlast_levelfield is set in the index config. - cli:
clear-cachecommand is deprecated and will be removed in the next major release. Usecache clearcommand instead.
Performance
- config: Configuration files are loaded 10x times faster.
- index: Number of operations processed by matcher reduced by 40%-95% depending on the number of addresses and entrypoints used.
- tzkt: Rate limit was increased. Try to set
connection_timeoutto a higher value if requests fail withConnectionTimeoutexception. - tzkt: Improved performance of response deserialization.
3.1.3 - 2021-11-15
Fixed
- codegen: Fixed missing imports in operation handlers.
- codegen: Fixed invalid imports and arguments in big_map handlers.
3.1.2 - 2021-11-02
Fixed
- Fixed crash occurred during synchronization of big map indexes.
3.1.1 - 2021-10-18
Fixed
- Fixed loss of realtime subscriptions occurred after TzKT API outage.
- Fixed updating schema hash in
schema approvecommand. - Fixed possible crash occurred while Hasura is not ready.
3.1.0 - 2021-10-12
Added
- New index class
HeadIndex(configuration:dipdup.config.HeadIndexConfig). Use this index type to handle head (limited block header content) updates. This index type is realtime-only: historical data won't be indexed during the synchronization stage. - Added three new commands:
schema approve,schema wipe, andschema export. Rundipdup schema --helpcommand for details.
Changed
- Triggering reindexing won't lead to dropping the database automatically anymore.
ReindexingRequiredErroris raised instead.--forbid-reindexingoption has become default. --reindexoption is removed. Usedipdup schema wipeinstead.- Values of
dipdup_schema.reindexfield updated to simplify querying database. Seedipdup.enums.ReindexingReasonclass for possible values.
Fixed
- Fixed
ReindexRequiredErrornot being raised when running DipDup after reindexing was triggered. - Fixed index config hash calculation. Hashes of existing indexes in a database will be updated during the first run.
- Fixed issue in
BigMapIndexcausing the partial loss of big map diffs. - Fixed printing help for CLI commands.
- Fixed merging storage which contains specific nested structures.
Improved
- Raise
DatabaseConfigurationErrorexception when project models are not compatible with GraphQL. - Another bunch of performance optimizations. Reduced DB pressure, speeded up parallel processing lots of indexes.
- Added initial set of performance benchmarks (run:
./scripts/run_benchmarks.sh)
3.0.4 - 2021-10-04
Improved
- A significant increase in indexing speed.
Fixed
- Fixed unexpected reindexing caused by the bug in processing zero- and single-level rollbacks.
- Removed unnecessary file IO calls that could cause
PermissionErrorexception in Docker environments. - Fixed possible violation of block-level atomicity during realtime indexing.
Changes
- Public methods of
TzktDatasourcenow return immutable sequences.
3.0.3 - 2021-10-01
Fixed
- Fixed processing of single-level rollbacks emitted before rolled back head.
3.0.2 - 2021-09-30
Added
- Human-readable
CHANGELOG.md🕺 - Two new options added to
dipdup runcommand:--forbid-reindexing– raiseReindexingRequiredErrorinstead of truncating database when reindexing is triggered for any reason. To continue indexing with existing database runUPDATE dipdup_schema SET reindex = NULL;--postpone-jobs– job scheduler won't start until all indexes are synchronized.
Changed
- Migration to this version requires reindexing.
dipdup_index.head_idforeign key removed.dipdup_headtable still contains the latest blocks from Websocket received by each datasource.
Fixed
- Removed unnecessary calls to TzKT API.
- Fixed removal of PostgreSQL extensions (
timescaledb,pgcrypto) by functiontruncate_databasetriggered on reindex. - Fixed creation of missing project package on
init. - Fixed invalid handler callbacks generated on
init. - Fixed detection of existing types in the project.
- Fixed race condition caused by event emitter concurrency.
- Capture unknown exceptions with Sentry before wrapping to
DipDupError. - Fixed job scheduler start delay.
- Fixed processing of reorg messages.
3.0.1 - 2021-09-24
Added
- Added
get_quoteandget_quotesmethods toTzKTDatasource.
Fixed
- Defer spawning index datasources until initial sync is complete. It helps to mitigate some WebSocket-related crashes, but initial sync is a bit slower now.
- Fixed possible race conditions in
TzKTDatasource. - Start
jobsscheduler after all indexes sync with a current head to speed up indexing.
Release notes
This section contains information about changes introduced with specific DipDup releases.
6.2.0
What's New
New interactive installer
Starting from this release, DipDup comes with an interactive installer to help you install necessary dependencies.
Run the command below in the terminal:
curl -Lsf https://dipdup.io/install.py | python
Follow the instructions to complete the installation.
Now you have dipdup command available systemwide! Run it without arguments to see available commands.
You can use dipdup install/update/uninstall commands to manage the local installation.
Project scaffolding
dipdup new command is now available to create a new project from a template. Run it and follow the questions; a new project will be created in the current directory. You can also use a replay file instead; see dipdup new --help for details.
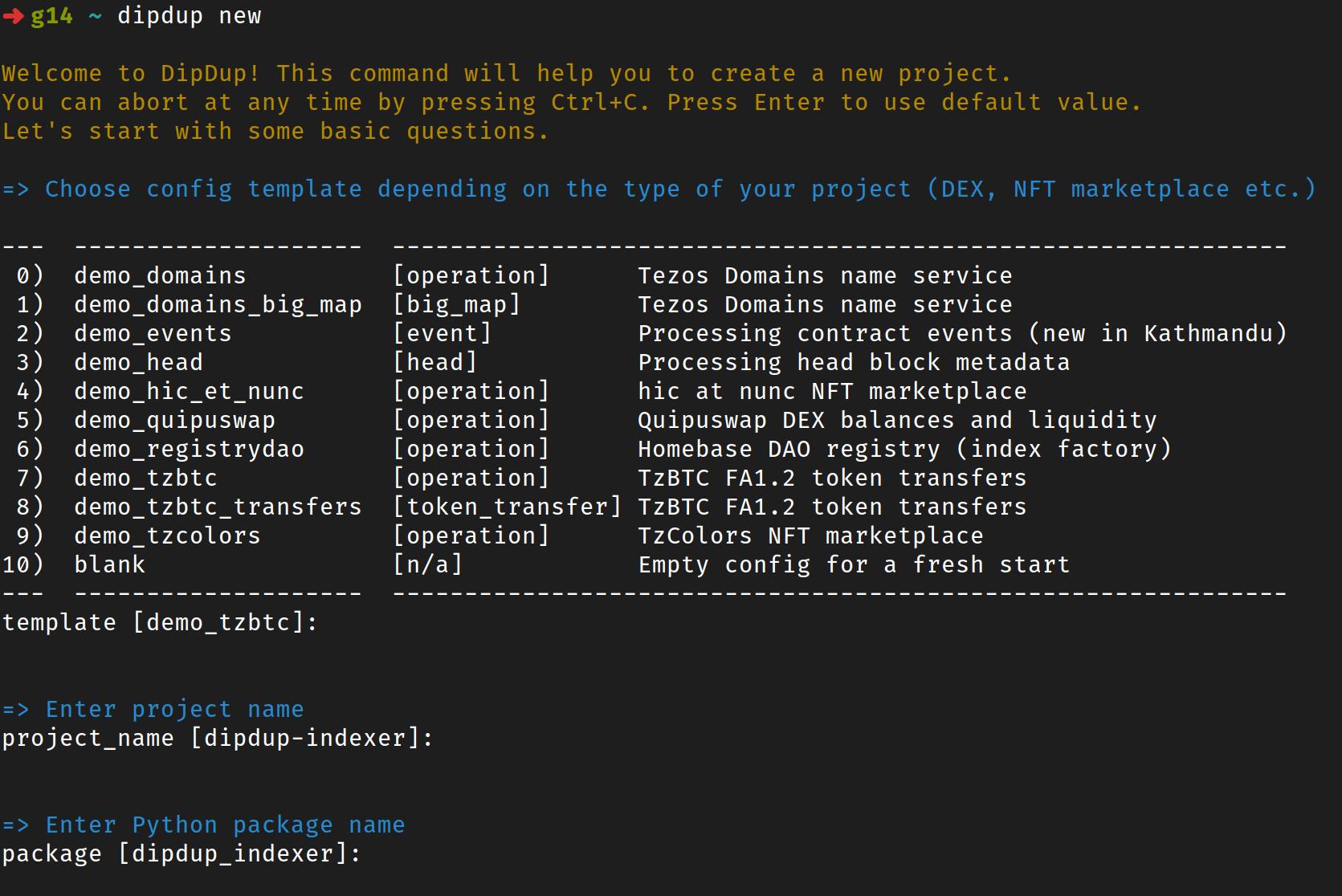
Kathmandu contract events
Kathmandu Tezos protocol upgrade has introduced contract events, a new way to interact with smart contracts. This index allows indexing events using strictly typed payloads. From the developer's perspective, it's similar to the big_map index with a few differences.
An example below is artificial since no known contracts in mainnet are currently using events.
contract: events_contract
tag: move
- callback: on_roll_event
contract: events_contract
tag: roll
- callback: on_other_event
contract: events_contract
Unlike big maps, contracts may introduce new event tags and payloads at any time, so the index must be updated accordingly.
async def on_move_event(
ctx: HandlerContext,
event: Event[MovePayload],
) -> None:
...
Each contract can have a fallback handler called for all unknown events so you can process untyped data.
async def on_other_event(
ctx: HandlerContext,
event: UnknownEvent,
) -> None:
...
Changes since 5.1.3
Added
- cli:
newcommand to create a new project interactively. - cli:
install/update/uninstallcommands to manage local DipDup installation. - index: New index kind
eventto process contract events. - install: New interactive installer based on pipx (
install.pyordipdup-install).
Fixed
- cli: Fixed commands that don't require a valid config yet crash with
ConfigurationError. - codegen: Fail on demand when
datamodel-codegenis not available. - codegen: Fixed Jinja2 template caching.
- config: Allow
sentry.dsnfield to be empty. - config: Fixed greedy environment variable regex.
- hooks: Raise a
FeatureAvailabilityHookinstead of a warning when trying to execute hooks on SQLite.
Improved
- cli: Detect
src/layout when guessing package path. - codegen: Improved cross-platform compatibility.
- config:
sentry.user_idoption to set user ID for Sentry (affects release adoption data). - sentry: Detect environment when not set in config (docker/gha/tests/local)
- sentry: Expose more tags under the
dipdupnamespace.
Performance
- cli: Up to 5x faster startup for some commands.
Security
- sentry: Prevent Sentry from leaking hostname if
server_nameis not set. - sentry: Notify about using Sentry when DSN is set or crash reporting is enabled.
Other
- ci: A significantly faster execution of GitHub Actions.
- docs: Updated "Contributing Guide" page.
6.0.0
⚠ Breaking Changes
- Project models in
models.pymust be subclassed fromdipdup.models.Modelinstead oftortoise.Model. - The deprecated
on_rollbackevent hook has been removed in favor ofon_index_rollback. - HTTP datasources no longer use caching.
cache showandcache clearcommands have been removed.http.cacheconfig flag has been removed. --logging-configoption has been removed. Use theloggingconfig section or set up logging manually.- Feature flag options of
runcommand have been removed. Use theadvancedconfig section instead.
Migration from 5.x
- Replace
tortoise.Modelimport withdipdup.models.Modelin yourmodels.pymodule. - Remove the
on_rollbackevent hook if it still persists in your project. Ensure thaton_index_rollback.pycontainsctx.rollbackcall, or remove it and calldipdup init. - If you have used
buffer_sizeconfig option, remove it to use database-level rollbacks. - Run
schema approvecommand with every schema you want to use with DipDup 6.0.
What's New
Seamless database-level rollbacks
The era of handling chain reorgs manually is finally over! Now when DipDup receives a reorg message from TzKT it just rewinds a database to the previous state reverting changes in backtracked blocks level by level. To make this possible, DipDup catches all database modifications and saves diffs in a separate table, dipdup_model_update (you don't need to access it directly).
# INSERT saved with no data, just drop this row on reorg.
trader = Trader(name='Alice', balance=100, active=True)
await trader.save()
# UPDATE saved with data old values to set them on reorg.
# Diff: {'balance': 100}
trader.balance = 200
await trader.save()
# DELETE saved with full copy of data. On reorg this row will be recreated with the same PK.
# Diff: {'name': 'Alice', 'balance': 200, 'active': True}
await trader.delete()
Bulk class methods like bulk_insert and bulk_update are supported too. However, for raw queries, DipDup uses prefetching (additional SELECT) to save original values. So, ReallyHugeTable.filter().delete() will create efficiently a full copy of the table in dipdup_model_update. Most likely you will never need to perform such queries in handlers, but keep that detail in mind.
Since the Ithacanet protocol, only two last blocks may be backtracked. We do not need to store older diffs, they are removed automatically. If you need to keep more levels or disable this feature, adjust rollback_depth config option.
advanced:
rollback_depth: 2 # 0 to disable
on_index_rollback event hook now looks like this:
from dipdup.context import HookContext
from dipdup.index import Index
async def on_index_rollback(
ctx: HookContext,
index: Index, # type: ignore[type-arg]
from_level: int,
to_level: int,
) -> None:
await ctx.execute_sql('on_index_rollback')
await ctx.rollback(
index=index.name,
from_level=from_level,
to_level=to_level,
)
TzKT buffer_size option remains available, but it's not required to handle chain reorgs anymore.
Crash dumps and automatic reporting
Now when DipDup catches unhandled exceptions, a crash dump will be saved to the temporary directory.
dipdup.exceptions.CallbackError: An error occured during callback execution
________________________________________________________________________________
`demo_token.hooks.on_restart` callback execution failed:
Exception:
Eliminate the reason of failure and restart DipDup.
________________________________________________________________________________
Crashdump saved to `/tmp/dipdup/crashdumps/veb7kz07.json`
This JSON file is the same data Sentry collects on crashes if integration is enabled. It includes a stack trace, local variables of each frame, and other information useful when investigating a crash. Attach this file when sending bug reports to GitHub Issues.
When preparing a crash dump Sentry can detect sensitive information like database passwords in the crash dump and remove it from the report. So it's generally safe to share the crash dump with the developers. Now you can also send these crash reports automatically to the Baking Bad team.
Your privacy matters; crash reporting is disabled by default. Simulate a crash with a random exception and inspect a crash dump before enabling this option to ensure that report doesn't contain secrets. Then add the following lines to your config:
advanced:
crash_reporting: True
Changes since 5.2.5
Added
- cli: Added
config export --fullflag to resolve templates before printing config. - config: Added
advanced.crash_reportingflag to enable reporting crashes to Baking Bad. - config: Added
advanced.rollback_depthfield, a number of levels to keep in a database for rollback. - context: Added
rollbackmethod to perform database rollback. - database: Added an internal
ModelUpdatemodel to store the latest database changes. - dipdup: Save Sentry crashdump in
/tmp/dipdup/crashdumps/XXXXXXX.jsonon a crash.
Fixed
- config: Do not perform env variable substitution in commented-out lines.
- prometheus: Fixed updating
dipdup_index_handlers_matched_totalmetric.
Changed
- codegen:
on_index_rollbackhook callsctx.rollbackby default. - database: Project models must be subclassed from
dipdup.models.Model
Removed
- cli:
--logging-configoption is removed. - cli: All
runcommand flags are removed. Use theadvancedsection of the config. - cli:
cache showandcache clearcommands are removed. - config:
http.cacheflag is removed. - hooks: Removed deprecated
on_rollbackhook. - index: Do not try to avoid single-level rollbacks by comparing operation hashes.
5.1.0
Migration from 5.0 (optional)
- Run
initcommand. Now you have two conflicting hooks:on_rollbackandon_index_rollback. Follow the guide below to perform the migration.ConflictingHooksErrorexception will be raised until then.
What's New
Per-index rollback hook
In this release, we continue to improve the rollback-handling experience, which became much more important since the Ithaca protocol reached mainnet. Let's briefly recap how DipDup currently processes chain reorgs before calling a rollback hook:
- If the
buffer_sizeoption of a TzKT datasource is set to a non-zero value, and there are enough data messages buffered when a rollback occurs, data is just dropped from the buffer, and indexing continues. - If all indexes in the config are
operationones, we can attempt to process a single-level rollback. All operations from rolled back block must be presented in the next one for rollback to succeed. If some operations are missing, theon_rollbackhook will be called as usual. - Finally, we can safely ignore indexes with a level lower than the rollback target. The index level is updated either on synchronization or when at least one related operation or bigmap diff has been extracted from a realtime message.
If none of these tricks have worked, we can't process a rollback without custom logic. Here's where changes begin. Before this release, every project contained the on_rollback hook, which receives datasource: IndexDatasource argument and from/to levels. Even if your deployment has thousands of indexes and only a couple of them are affected by rollback, you weren't able to easily find out which ones.
Now on_rollback hook is deprecated and superseded by the on_index_rollback one. Choose one of the following options:
- You haven't touched the
on_rollbackhook since project creation. Runinitcommand and removehooks/on_rollbackandsql/on_rollbackdirectories in project root. Default action (reindexing) has not changed. - You have some custom logic in
on_rollbackhook and want to leave it as-is for now. You can ignore introduced changes at least till the next major release. - You have implemented per-datasource rollback logic and are ready to switch to the per-index one. Run
init, move your code to theon_index_rollbackhook and deleteon_rollbackone. Note, you can access rolled back datasource viaindex.datasource.
Token transfer index
Sometimes implementing an operation index is overkill for a specific task. An existing alternative is to use a big_map index to process only the diffs of selected big map paths. However, you still need to have a separate index for each contract of interest, which is very resource-consuming. A widespread case is indexing FA1.2/FA2 token contracts. So, this release introduces a new token_transfer index:
indexes:
transfers:
kind: token_transfer
datasource: tzkt
handlers:
- callback: transfers
The TokenTransferData object is passed to the handler on each operation, containing only information enough to process a token transfer.
config env command to generate env-files
Generally, It's good to separate a project config from deployment parameters, and DipDup has multiple options to achieve this. First of all, multiple configs can be chained successively, overriding top-level sections. Second, the DipDup config can contain docker-compose-style environment variable declarations. Let's say your config contains the following content:
database:
kind: postgres
host: db
port: 5432
user: ${POSTGRES_USER:-dipdup}
password: ${POSTGRES_PASSWORD:-changeme}
database: ${POSTGRES_DB:-dipdup}
You can generate an env-file to use with this exact config:
$ dipdup -c dipdup.yml -c dipdup.docker.yml config env
POSTGRES_USER=dipdup
POSTGRES_PASSWORD=changeme
POSTGRES_DB=dipdup
The environment of your current shell is also taken into account:
$ POSTGRES_DB=foobar dipdup -c dipdup.yml -c dipdup.docker.yml config env
POSTGRES_USER=dipdup
POSTGRES_PASSWORD=changeme
POSTGRES_DB=foobar # <- set from current env
Use -f <filename> option to save output on disk instead of printing to stdout. After you have modified the env-file according to your needs, you can apply it the way which is more convenient to you:
With dipdup --env-file / -e option:
dipdup -e prod.env <...> run
When using docker-compose:
services:
indexer:
...
env_file: prod.env
Keeping framework up-to-date
A bunch of new tags is now pushed to the Docker Hub on each release in addition to the X.Y.Z one: X.Y and X. That way, you can stick to a specific release without the risk of leaving a minor/major update unattended (friends don't let friends use latest 😉). The -pytezos flavor is also available for each tag.
FROM dipdup/dipdup:5.1
...
In addition, DipDup will poll GitHub for new releases on each command which executes reasonably long and print a warning when running an outdated version. You can disable these checks with advanced.skip_version_check flag.
Pro tip: you can also enable notifications on the GitHub repo page with 👁 Watch -> Custom -> tick Releases -> Apply to never miss a fresh DipDup release.
Changelog
See full 5.1.0 changelog here.
5.0.0
⚠ Breaking Changes
- Python versions 3.8 and 3.9 are no longer supported.
bcddatasource has been removed.- Two internal tables were added,
dipdup_contract_metadataanddipdup_token_metadata. - Some methods of
tzktdatasource have changed their signatures and behavior. - Dummy
advanced.oneshotconfig flag has been removed. - Dummy
schema approve --hashescommand flag has been removed. docker initcommand has been removed.ReindexingReasonenumeration items have been changed.
Migration from 4.x
- Ensure that you have a
python = "^3.10"dependency inpyproject.toml. - Remove
bcddatasources from config. Usemetadatadatasource instead to fetch contract and token metadata. - Update
tzktdatasource method calls as described below. - Run the
dipdup schema approvecommand on every database you use with 5.0.0. - Update usage of
ReindexingReasonenumeration if needed.
What's New
Process realtime messages with lag
Chain reorgs have occurred much recently since the Ithaca protocol reached mainnet. The preferable way to deal with rollbacks is the on_rollback hook. But if the logic of your indexer is too complex, you can buffer an arbitrary number of levels before processing to avoid reindexing.
datasources:
tzkt_mainnet:
kind: tzkt
url: https://api.tzkt.io
buffer_size: 2
DipDup tries to remove backtracked operations from the buffer instead emitting rollback. Ithaca guarantees operations finality after one block and blocks finality after two blocks, so to completely avoid reorgs, buffer_size should be 2.
BCD API takedown
Better Call Dev API was officially deprecated in February. Thus, it's time to go for bcd datasource. In DipDup, it served the only purpose of fetching contract and token metadata. Now there's a separate metadata datasource which do the same thing but better. If you have used bcd datasource for custom requests, see How to migrate from BCD to TzKT API article.
TzKT batch request pagination
Historically, most TzktDatasource methods had a page iteration logic hidden inside. The quantity of items returned by TzKT in a single request is configured in HTTPConfig.batch_size and defaulted to 10.000. Before this release, three requests would be performed by the get_big_map method to fetch 25.000 big map keys, leading to performance degradation and extensive memory usage.
| affected method | response size in 4.x | response size in 5.x |
|---|---|---|
get_similar_contracts | unlimited | max. datasource.request_limit |
get_originated_contracts | unlimited | max. datasource.request_limit |
get_big_map | unlimited | max. datasource.request_limit |
get_contract_big_maps | unlimited | max. datasource.request_limit |
get_quotes | first datasource.request_limit | max. datasource.request_limit |
All paginated methods now behave the same way. You can either iterate over pages manually or use iter_... helpers.
datasource = ctx.get_tzkt_datasource('tzkt_mainnet')
batch_iter = datasource.iter_big_map(
big_map_id=big_map_id,
level=last_level,
)
async for key_batch in batch_iter:
for key in key_batch:
...
Metadata interface for TzKT integration
Starting with 5.0 you can store and expose custom contract and token metadata in the same format DipDup Metadata service does for TZIP-compatible metadata.
Enable this feature with advanced.metadata_interface flag, then update metadata in any callback:
await ctx.update_contract_metadata(
network='mainnet',
address='KT1...',
metadata={'foo': 'bar'},
)
Metadata stored in dipdup_contract_metadata and dipdup_token_metadata tables and available via GraphQL and REST APIs.
Prometheus integration
This version introduces initial Prometheus integration. It could help you set up monitoring, find performance issues in your code, and so on. To enable this integration, add the following lines to the config:
prometheus:
host: 0.0.0.0
Changes since 4.2.7
Added
- config: Added
customsection to store arbitrary user data. - metadata: Added
metadata_interfacefeature flag to expose metadata in TzKT format. - prometheus: Added ability to expose Prometheus metrics.
- tzkt: Added ability to process realtime messages with lag.
- tzkt: Added missing fields to the
HeadBlockDatamodel. - tzkt: Added
iter_...methods to iterate over item batches.
Fixed
- config: Fixed default SQLite path (
:memory:). - prometheus: Fixed invalid metric labels.
- tzkt: Fixed pagination in several getter methods.
- tzkt: Fixed data loss when
skip_historyoption is enabled. - tzkt: Fixed crash in methods that do not support cursor pagination.
- tzkt: Fixed possible OOM while calling methods that support pagination.
- tzkt: Fixed possible data loss in
get_originationsandget_quotesmethods.
Changed
- tzkt: Added
offsetandlimitarguments to all methods that support pagination.
Removed
- bcd: Removed
bcddatasource and config section. - cli: Removed
docker initcommand. - cli: Removed dummy
schema approve --hashesflag. - config: Removed dummy
advanced.oneshotflag.
Performance
- dipdup: Use fast
orjsonlibrary instead of built-injsonwhere possible.
4.2.0
What's new
ipfs datasource
While working with contract/token metadata, a typical scenario is to fetch it from IPFS. DipDup now has a separate datasource to perform such requests.
datasources:
ipfs:
kind: ipfs
url: https://ipfs.io/ipfs
You can use this datasource within any callback. Output is either JSON or binary data.
ipfs = ctx.get_ipfs_datasource('ipfs')
file = await ipfs.get('QmdCz7XGkBtd5DFmpDPDN3KFRmpkQHJsDgGiG16cgVbUYu')
assert file[:4].decode()[1:] == 'PDF'
file = await ipfs.get('QmSgSC7geYH3Ae4SpUHy4KutxqNH9ESKBGXoCN4JQdbtEz/package.json')
assert file['name'] == 'json-buffer'
You can tune HTTP connection parameters with the http config field, just like any other datasource.
Sending arbitrary requests
DipDup datasources do not cover all available methods of underlying APIs. Let's say you want to fetch protocol of the chain you're currently indexing from TzKT:
tzkt = ctx.get_tzkt_datasource('tzkt_mainnet')
protocol_json = await tzkt.request(
method='get',
url='v1/protocols/current',
cache=False,
weigth=1, # ratelimiter leaky-bucket drops
)
assert protocol_json['hash'] == 'PtHangz2aRngywmSRGGvrcTyMbbdpWdpFKuS4uMWxg2RaH9i1qx'
Datasource HTTP connection parameters (ratelimit, backoff, etc.) are applied on every request.
Firing hooks outside of the current transaction
When configuring a hook, you can instruct DipDup to wrap it in a single database transaction:
hooks:
my_hook:
callback: my_hook
atomic: True
Until now, such hooks could only be fired according to jobs schedules, but not from a handler or another atomic hook using ctx.fire_hook method. This limitation is eliminated - use wait argument to escape the current transaction:
async def handler(ctx: HandlerContext, ...) -> None:
await ctx.fire_hook('atomic_hook', wait=False)
Spin up a new project with a single command
Cookiecutter is an excellent jinja2 wrapper to initialize hello-world templates of various frameworks and toolkits interactively. Install python-cookiecutter package systemwide, then call:
cookiecutter https://github.com/dipdup-io/cookiecutter-dipdup
Advanced scheduler configuration
DipDup utilizes apscheduler library to run hooks according to schedules in jobs config section. In the following example, apscheduler spawns up to three instances of the same job every time the trigger is fired, even if previous runs are in progress:
advanced:
scheduler:
apscheduler.job_defaults.coalesce: True
apscheduler.job_defaults.max_instances: 3
See apscheduler docs for details.
Note that you can't use executors from apscheduler.executors.pool module - ConfigurationError exception raised then. If you're into multiprocessing, I'll explain why in the next paragraph.
About the present and future of multiprocessing
It's impossible to use apscheduler pool executors with hooks because HookContext is not pickle-serializable. So, they are forbidden now in advanced.scheduler config. However, thread/process pools can come in handy in many situations, and it would be nice to have them in DipDup context. For now, I can suggest implementing custom commands as a workaround to perform any resource-hungry tasks within them. Put the following code in <project>/cli.py:
from contextlib import AsyncExitStack
import asyncclick as click
from dipdup.cli import cli, cli_wrapper
from dipdup.config import DipDupConfig
from dipdup.context import DipDupContext
from dipdup.utils.database import tortoise_wrapper
@cli.command(help='Run heavy calculations')
@click.pass_context
@cli_wrapper
async def do_something_heavy(ctx):
config: DipDupConfig = ctx.obj.config
url = config.database.connection_string
models = f'{config.package}.models'
async with AsyncExitStack() as stack:
await stack.enter_async_context(tortoise_wrapper(url, models))
...
if __name__ == '__main__':
cli(prog_name='dipdup', standalone_mode=False)
Then use python -m <project>.cli instead of dipdup as an entrypoint. Now you can call do-something-heavy like any other dipdup command. dipdup.cli:cli group handles arguments and config parsing, graceful shutdown, and other boilerplate. The rest is on you; use dipdup.dipdup:DipDup.run as a reference. And keep in mind that Tortoise ORM is not thread-safe. I aim to implement ctx.pool_apply and ctx.pool_map methods to execute code in pools with magic within existing DipDup hooks, but no ETA yet.
That's all, folks! As always, your feedback is very welcome 🤙
4.1.0
Migration from 4.0 (optional)
- Run
dipdup schema initon the existing database to enabledipdup_head_statusview and REST endpoint.
What's New
Index only the current state of big maps
big_map indexes allow achieving faster processing times than operation ones when storage updates are the only on-chain data your dapp needs to function. With this DipDup release, you can go even further and index only the current storage state, ignoring historical changes.
indexes:
foo:
kind: big_map
...
skip_history: never|once|always
When this option is set to once, DipDup will skip historical changes only on initial sync and switch to regular indexing afterward. When the value is always, DipDup will fetch all big map keys on every restart. Preferrable mode depends on your workload.
All big map diffs DipDup pass to handlers during fast sync have action field set to BigMapAction.ADD_KEY. Keep in mind that DipDup fetches all keys in this mode, including ones removed from the big map. If needed, you can filter out the latter by BigMapDiff.data.active field.
New datasource for contract and token metadata
Since the first version DipDup allows to fetch token metadata from Better Call Dev API with bcd datasource. Now it's time for a better solution. Firstly, BCD is far from being reliable in terms of metadata indexing. Secondly, spinning up your own instance of BCD requires significant effort and computing power. Lastly, we plan to deprecate Better Call Dev API soon (but do not worry - it won't affect the explorer frontend).
Luckily, we have dipdup-metadata, a standalone companion indexer for DipDup written in Go. Configure a new datasource in the following way:
datasources:
metadata:
kind: metadata
url: https://metadata.dipdup.net
network: mainnet|ghostnet|limanet
Now you can use it anywhere in your callbacks:
datasource = ctx.datasources['metadata']
token_metadata = await datasource.get_token_metadata(address, token_id)
bcd datasource will remain available for a while, but we discourage using it for metadata processing.
Nested packages for hooks and handlers
Callback modules are no longer have to be in top-level hooks/handlers directories. Add one or multiple dots to the callback name to define nested packages:
package: indexer
hooks:
foo.bar:
callback: foo.bar
After running init command, you'll get the following directory tree (shortened for readability):
indexer
├── hooks
│ ├── foo
│ │ ├── bar.py
│ │ └── __init__.py
│ └── __init__.py
└── sql
└── foo
└── bar
└── .keep
The same rules apply to handler callbacks. Note that callback field must be a valid Python package name - lowercase letters, underscores, and dots.
New CLI commands and flags
-
schema initis a new command to prepare a database for running DipDip. It will create tables based on your models, then callon_reindexSQL hook to finish preparation - the same things DipDup does when run on a clean database. -
hasura configure --forceflag allows to configure Hasura even if metadata hash matches one saved in database. It may come in handy during development. -
init --keep-schemasflag makes DipDup preserve contract JSONSchemas. Usually, they are removed after generating typeclasses withdatamodel-codegen, but you can keep them to convert to other formats or troubleshoot codegen issues.
Built-in dipdup_head_status view and REST endpoint
DipDup maintains several internal models to keep its state. As Hasura generates GraphQL queries and REST endpoints for those models, you can use them for monitoring. However, some SaaS monitoring solutions can only check whether an HTTP response contains a specific word or not. For such cases dipdup_head_status view was added - a simplified representation of dipdup_head table. It returns OK when datasource received head less than two minutes ago and OUTDATED otherwise. Latter means that something's stuck, either DipDup (e.g., because of database deadlock) or TzKT instance. Or maybe the whole Tezos blockchain, but in that case, you have problems bigger than indexing.
$ curl "http://127.0.0.1:41000/api/rest/dipdupHeadStatus?name=https%3A%2F%2Fapi.tzkt.io"
{"dipdupHeadStatus":[{"status":"OUTDATED"}]}%
Note that dipdup_head update may be delayed during sync even if the --early-realtime flag is enabled, so don't rely exclusively on this endpoint.
Changelog
Added
- cli: Added
schema initcommand to initialize database schema. - cli: Added
--forceflag tohasura configurecommand. - codegen: Added support for subpackages inside callback directories.
- hasura: Added
dipdup_head_statusview and REST endpoint. - index: Added an ability to skip historical data while synchronizing
big_mapindexes. - metadata: Added
metadatadatasource. - tzkt: Added
get_big_mapandget_contract_big_mapsdatasource methods.
4.0.0
⚠ Breaking Changes
run --oneshotoption is removed. The oneshot mode (DipDup stops after the sync is finished) applies automatically whenlast_levelfield is set in the index config.clear-cachecommand is removed. Usecache clearinstead.
Migration from 3.x
- Run
dipdup initcommand to generateon_synchronizedhook stubs. - Run
dipdup schema approvecommand on every database you want to use with 4.0.0. Runningdipdup migrateis not necessary sincespec_versionhasn't changed in this release.
What's New
Performance optimizations
Overall indexing performance has been significantly improved. Key highlights:
- Configuration files are loaded 10x times faster. The more indexes in the project, the more noticeable difference is.
- Significantly reduced CPU usage in realtime mode.
- Datasource default HTTP connection options optimized for a reasonable balance between resource consumption and indexing speed.
Also, two new flags were added to improve DipDup performance in several scenarios: merge_subscriptions and early_relatime. See this paragraph for details.
Configurable action on reindex
There are several reasons that trigger reindexing:
| reason | description |
|---|---|
manual | Reindexing triggered manually from callback with ctx.reindex. |
migration | Applied migration requires reindexing. Check release notes before switching between major DipDup versions to be prepared. |
rollback | Reorg message received from TzKT, and can not be processed. |
config_modified | One of the index configs has been modified. |
schema_modified | Database schema has been modified. Try to avoid manual schema modifications in favor of SQL hooks. |
Now it is possible to configure desirable action on reindexing triggered by the specific reason.
| action | description |
|---|---|
exception (default) | Raise ReindexingRequiredError and quit with error code. The safest option since you can trigger reindexing accidentally, e.g., by a typo in config. Don't forget to set up the correct restart policy when using it with containers. |
wipe | Drop the whole database and start indexing from scratch. Be careful with this option! |
ignore | Ignore the event and continue indexing as usual. It can lead to unexpected side-effects up to data corruption; make sure you know what you are doing. |
To configure actions for each reason, add the following section to DipDup config:
advanced:
...
reindex:
manual: wipe
migration: exception
rollback: ignore
config_modified: exception
schema_modified: exception
New CLI commands and flags
| command or flag | description |
|---|---|
cache show | Get information about file caches used by DipDup. |
config export | Print config after resolving all links and variables. Add --unsafe option to substitute environment variables; default values from config will be used otherwise. |
run --early-realtime | Establish a realtime connection before all indexes are synchronized. |
run --merge-subscriptions | Subscribe to all operations/big map diffs during realtime indexing. This flag helps to avoid reaching TzKT subscriptions limit (currently 10000 channels). Keep in mind that this option could significantly improve RAM consumption depending on the time required to perform a sync. |
status | Print the current status of indexes from the database. |
advanced top-level config section
This config section allows users to tune system-wide options, either experimental or unsuitable for generic configurations.
| field | description |
|---|---|
early_realtimemerge_subscriptionspostpone_jobs | Another way to set run command flags. Useful for maintaining per-deployment configurations. |
reindex | Configure action on reindexing triggered. See this paragraph for details. |
CLI flags have priority over self-titled AdvancedConfig fields.
aiosignalrcore replaced with pysignalr
It may not be the most noticeable improvement for end-user, but it still deserves a separate paragraph in this article.
Historically, DipDup used our own fork of signalrcore library named aiosignalrcore. This project aimed to replace the synchronous websocket-client library with asyncio-ready websockets. Later we discovered that required changes make it hard to maintain backward compatibility, so we have decided to rewrite this library from scratch. So now you have both a modern and reliable library for SignalR protocol and a much more stable DipDup. Ain't it nice?
Changes since 3.1.3
This is a combined changelog of -rc versions released since the last stable release until this one.
Added
- cli: Added
run --early-realtimeflag to establish a realtime connection before all indexes are synchronized. - cli: Added'run --merge-subscriptions` flag to subscribe to all operations/big map diffs during realtime indexing.
- cli: Added
statuscommand to print the current status of indexes from the database. - cli: Added
config export [--unsafe]command to print config after resolving all links and variables. - cli: Added
cache showcommand to get information about file caches used by DipDup. - config: Added
first_levelandlast_leveloptional fields toTemplateIndexConfig. These limits are applied after ones from the template itself. - config: Added
daemonboolean field toJobConfigto run a single callback indefinitely. Conflicts withcrontabandintervalfields. - config: Added
advancedtop-level section. - hooks: Added
on_synchronizedhook, which fires each time all indexes reach realtime state.
Fixed
- cli: Fixed config not being verified when invoking some commands.
- cli: Fixed crashes and output inconsistency when piping DipDup commands.
- cli: Fixed missing
schema approve --hashesargument. - cli: Fixed
schema wipe --immuneflag being ignored. - codegen: Fixed contract address used instead of an alias when typename is not set.
- codegen: Fixed generating callback arguments for untyped operations.
- codegen: Fixed missing imports in handlers generated during init.
- coinbase: Fixed possible data inconsistency caused by caching enabled for method
get_candles. - hasura: Fixed unnecessary reconfiguration in restart.
- http: Fixed increasing sleep time between failed request attempts.
- index: Fixed
CallbackErrorraised instead ofReindexingRequiredErrorin some cases. - index: Fixed crash while processing storage of some contracts.
- index: Fixed incorrect log messages, remove duplicate ones.
- index: Fixed invocation of head index callback.
- index: Fixed matching of untyped operations filtered by
sourcefield (@pravin-d). - tzkt: Fixed filtering of big map diffs by the path.
- tzkt: Fixed
get_originated_contractsandget_similar_contractsmethods whose output was limited toHTTPConfig.batch_sizefield. - tzkt: Fixed lots of SignalR bugs by replacing
aiosignalrcorelibrary withpysignalr. - tzkt: Fixed processing operations with entrypoint
default. - tzkt: Fixed regression in processing migration originations.
- tzkt: Fixed resubscribing when realtime connectivity is lost for a long time.
- tzkt: Fixed sending useless subscription requests when adding indexes in runtime.
Changed
- cli:
schema wipecommand now requires confirmation when invoked in the interactive shell. - cli:
schema approvecommand now also causes a recalculation of schema and index config hashes. - index: DipDup will recalculate respective hashes if reindexing is triggered with
config_modified: ignoreorschema_modified: ignorein advanced config.
Removed
- cli: Removed deprecated
run --oneshotargument andclear-cachecommand.
Performance
- config: Configuration files are loaded 10x times faster.
- index: Checks performed on each iteration of the main DipDup loop are slightly faster now.
- index: Number of operations processed by matcher reduced by 40%-95% depending on the number of addresses and entrypoints used.
- tzkt: Improved performance of response deserialization.
- tzkt: Rate limit was increased. Try to set
connection_timeoutto a higher value if requests fail withConnectionTimeoutexception.
DipDup contribution guide
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
General
- All code in this repository MUST be licensed under the MIT License.
- Python code in this repository MUST run on Python 3.10. It also SHOULD run on Python 3.11. Using modern language features is encouraged.
- Python code in this repository MUST run in Linux, macOS, Docker, and
amd64/arm64environments. Windows SHOULD be supported as well. - We use the Poetry package manager and GNU Make to set up the development environment. You SHOULD install both tools and run
make helpto see available shortcuts. - Developers SHOULD have fun while contributing to the project.
GitHub
- Branch names MUST follow
prefix/short-descriptionformat. Prefixes currently in use:featfor features,fixfor bugfixes,docsfor documentation,expfor experiments,auxfor everything else. - Commits in pull requests MUST be squashed when merging to
master. - Issues and pull requests MUST have a descriptive title; they SHOULD be linked to each other, appropriately labeled, and assigned to maintainers while in progress.
Codestyle
- We use the following combo of linters and formatters:
isort,black,ruff,mypy. All linter checks MUST pass before merging code tomaster(CI will fail otherwise). - Single quotes MUST be used for string literals.
- Meaningful comments are highly RECOMMENDED to begin with
# NOTE:,# TODO:, or# FIXME:. - f-string formatting is RECOMMENDED over other methods. Logging is an exception to this rule.
Packaging
- All dependencies MUST be declared in
pyproject.tomlfile. - Non-development dependencies MUST be pinned to non-breaking versions (e.g.
^1.2.3). - Core dependencies that we patch MUST be pinned to specific versions (e.g.
1.2.3).
Releases
- Release versions MUST conform to Semantic Versioning. Releases that introduce breaking changes MUST be major ones.
- Only the latest major version is supported in general. Critical fixes MAY be backported to the previous major release. To do so, create an
aux/X.Y.Zbranch from the latest stable tag, bump the DipDup version manually, and add a new tag.
Changelog
- All changes that affect user (developer) experience MUST be documented in the CHANGELOG.md file.
- Changes that significantly affect DipDup maintainers' experience MAY be documented in the CHANGELOG.md file.
- The changelog MUST conform to the "Keep a Changelog" specification (CI will break otherwise).
- Lines describing changes MUST be sorted and begin with DipDup module name (
index: Added ...).
Documentation
- A page in Release Notes SHOULD accompany all major releases.
- All internal links MUST be created with
{{ #summary ...shortcodes. - All values used in project templates MUST be replaced with
{{ #cookiecutter ...shortcodes.
Security
- GitHub alerts about dependencies that contain vulnerabilities MUST be investigated and resolved as soon as possible.
- Security-related bugfixes MUST be mentioned in the changelog under the "Security" section.
Privacy
- Crash reporting MUST be opt-in (disabled by default) both in config and project templates.
- Sentry events and crash reports MUST NOT contain any sensitive information (IP addresses, hostnames, etc.)
- DipDup SHOULD NOT perform network requests to APIs not defined in config as datasources. Current exceptions: GitHub.
Docker images
- DipDup dockerfiles use autogenerated
requirements.txtfiles. Maintainers MUST runmake updatescript on every change in dependencies. - Docker images for stable releases MUST be published on Docker Hub. They MAY also be published on GHCR.
- Maintainers MAY publish arbitrary images on GHCR and remove them when not needed.
Installer
- Installer module MUST depend on Python stdlib only.
Scaffolding
- Project templates SHOULD cover all index types available in DipDup.
- They also MAY contain additional features and integrations.
Demo projects
- Demos are stored in
demosroot directory. They MUST be generated automatically from project templates using replay files. - Maintainers SHOULD run
make demos replayscommand regularly to ensure that demo projects are up to date.
This page or paragraph is yet to be written. Come back later.
Tests
Code Review
MIT License
Copyright (c) 2021 Baking Bad
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.